What are embeddings, and why are they great for code impact analysis?
Contents
- How AI embeddings work
- Feeding embedding models better code data
- Using embeddings for mass-scale code search
- Birds-eye visualization of a codebase
- Smart sampling for relevant recommendations
- Faster debugging by clustering build errors
- Clustering search results from a recipe run
- Using embeddings for code with Moderne
Embeddings are a powerful technique in machine learning, enabling computers to understand and process various types of data, including text, images, and even code, by converting them into numerical representations that AI models can interpret.
By representing code as numerical vectors, embeddings make it possible for models to analyze patterns, understand context, and perform advanced tasks like refactoring or dependency management—essentially it’s turning code into data that AI can reason about. This capability is critical for tasks like code impact analysis, where understanding how changes to one part of the codebase might affect others is essential.
Let’s dive deeper into how embeddings work and then look at some specific examples of using them for large-scale code impact analysis.
How AI embeddings work
Embeddings are about attaching numbers to words. These numbers can then be leveraged by AI to discover relationships among the words. To help in understanding how such numeral representations work, let’s start with a classic AI case: predicting whether an email is spam. Early techniques would be programmed to generate vectors where each entry represented a specific feature, such as the length of the email, whether it contained phrases like “click here to win” or “free,” or whether the sender was someone you had previously emailed, as shown in Figure 1.
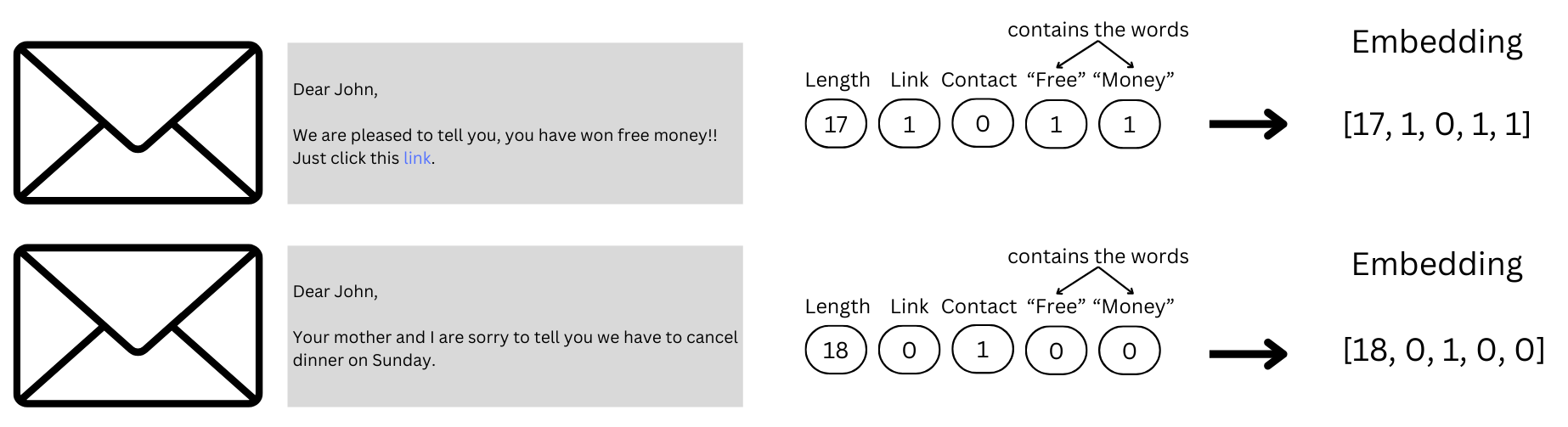
That means we can train a model to take these vectors as inputs, since they have no way of understanding the words in the email without pre-processing. Intuitively, these vectors are quite useful for tagging spam mail. A model might discern that if you have someone not in your contacts who emails you something containing the words “free” and “money” then the email is probably one you cannot trust.
What if the task changes. Maybe, you want to know if an email has positive vibes or negative vibes. In this case, you would add features for if the words “happy” or “pleased” or “sorry” are present in the email. You might start realizing that the features have to contain information that is useful to complete the task at hand.
In today’s world of AI, instead of pre-defining the features and manually preprocessing the text into numerical representations, we can rely on models that themselves learn to generate embeddings (naturally, we call these embedding models). It turns out that letting the models figure out by themselves how to generate these embeddings leads to better results. While some embedding models are task-specific, general models also exist that can generate embeddings without being tied to a specific task.
A few examples of modern general embedding models are word2vec, code2vec, or LLMs such as BAAI general embedding (BGE). Let’s use Figure 2 to explain how words can be mapped to a vector space—that is, how embeddings are assigned to words.
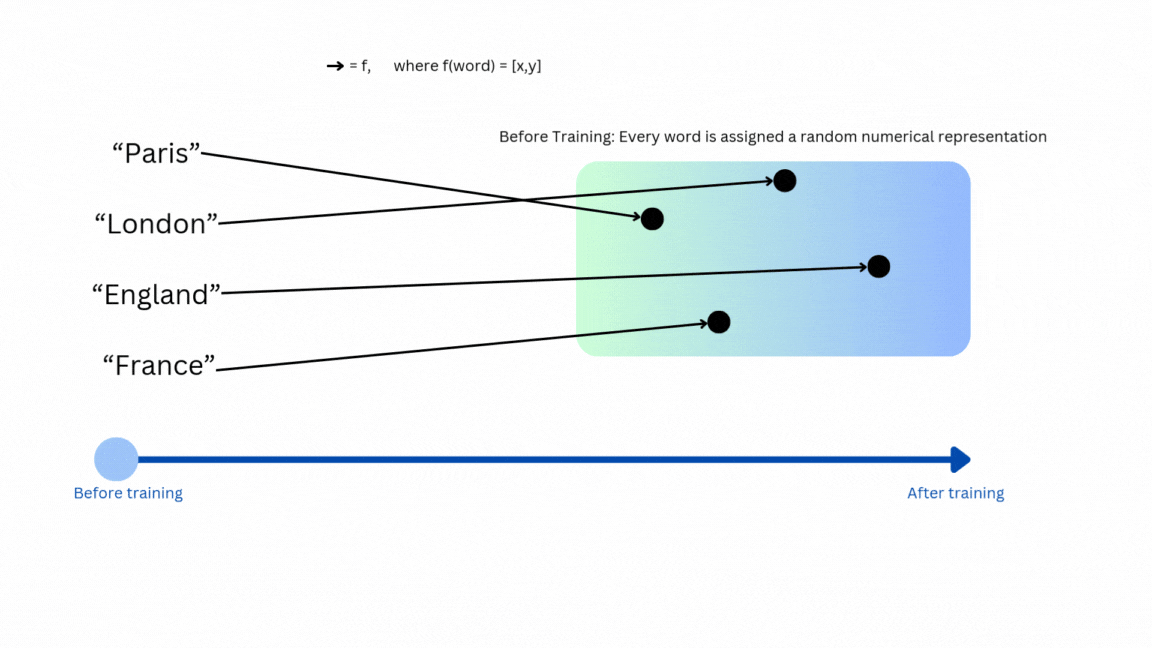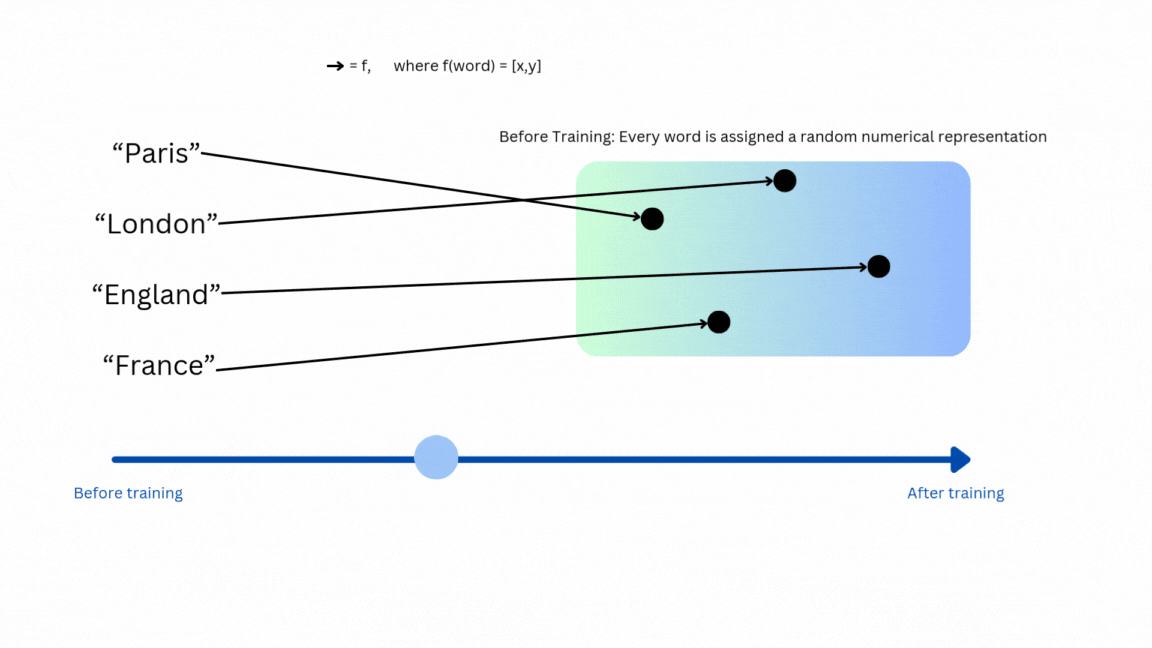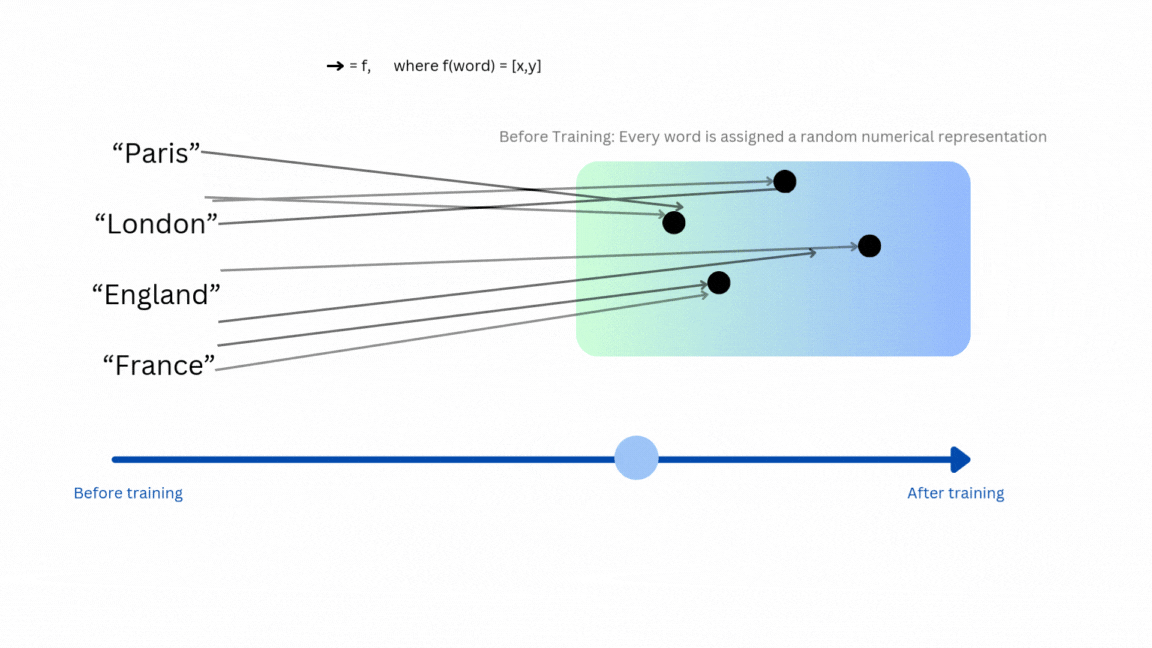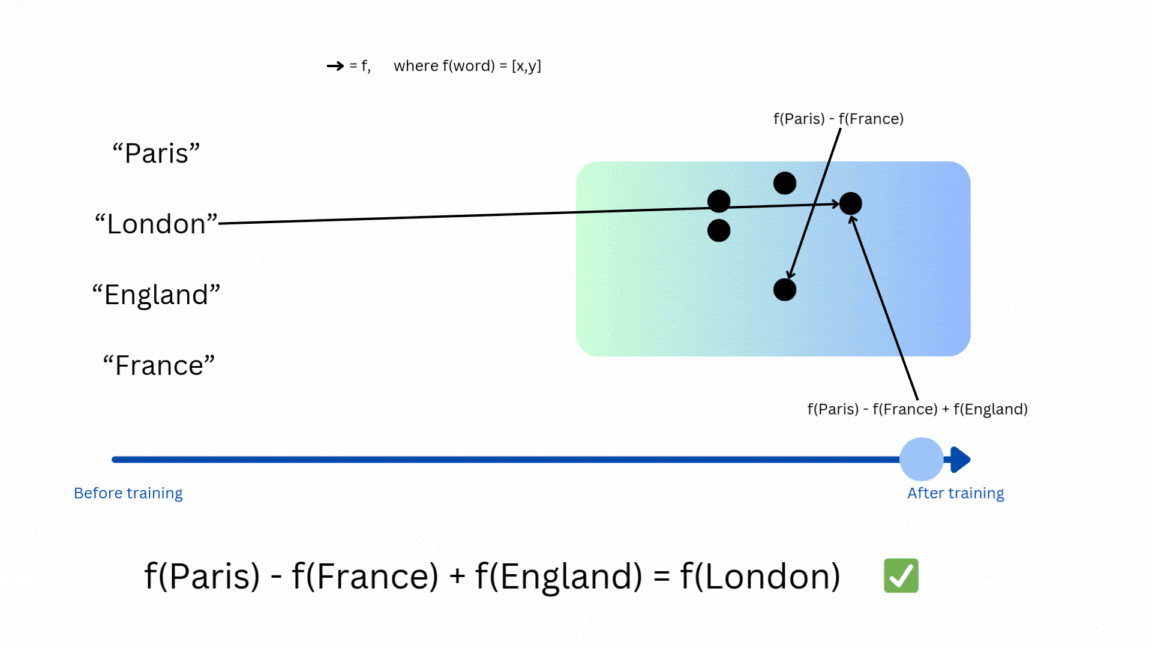
I recommend this video from 3Blue1Brown (at this particular time stamp) if you’re interested in seeing more examples of how these embeddings can represent words.
Once the mapping function from a concept to the embedding space is well trained, you can expect to have similar concepts to have vectors that are near each other. You can measure the similarity between two vectors using various metrics, for example euclidean distance or cosine similarity.
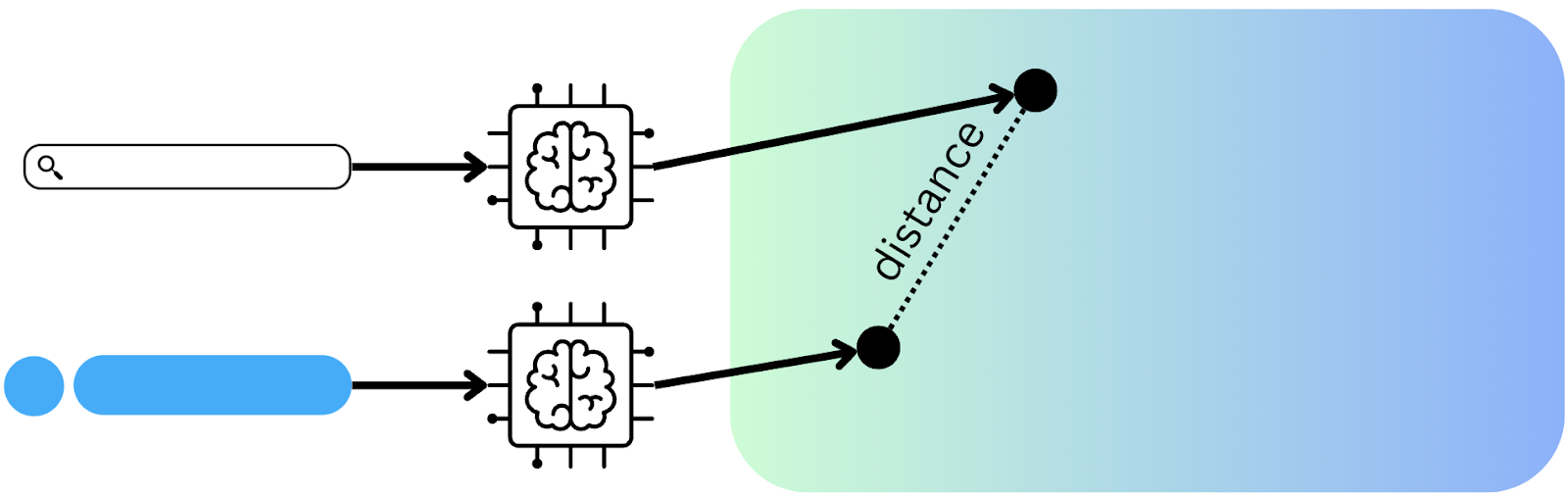
One thing to keep in mind is that even if you have the best embedding model, the embedding is only as good as the input—especially with code.
Feeding embedding models better code data
When it comes to applying embeddings to coding use cases, it’s all about the data—and not just any data. While source code might seem like an abundant resource, traditional representations fall short. Code-as-text and Abstract Syntax Trees (ASTs) fail to capture the full depth of information required to understand a codebase.
Why? Because code is more than syntax. It’s a structured language governed by strict grammar and complex dependencies, with type information that only a compiler can resolve deterministically. These rich details are invisible to text-based and AST representations, leaving critical insights untapped by AI.
For example, if you’re going to try to answer even a simple question about where a particular logging library is used, you’ll find that code-as-text may not have reference to the library. Imagine a logger instance inherited as a protected field from a base class that is defined in a binary dependency. The import statement that identifies which logging library that logger is coming from is in the binary dependency, not in the text of the call site.
That’s where the Lossless Semantic Tree (LST) comes in—a better, more comprehensive data source for code. Unlike traditional methods, LSTs retain type attribution and dependencies directly from the source code. They transform code into a machine-readable, lossless representation, enabling precise and deterministic analysis and transformations. For the logging example above, if you were to generate an embedding solely using the code-as-text, you would miss that critical nuance—you need that extra information the LST holds.
Let’s walk through some specific examples of embeddings in use with Moderne.
Using embeddings for mass-scale code search
Using embeddings for code search provides an efficient way to identify related code instances without needing to know the exact structure or methods beforehand. In large codebases, such as those with hundreds of repositories, manually searching for method invocations or patterns can be overwhelming and time-consuming.
Embeddings address this by converting both queries and method signatures into vector representations. By comparing these vectors, it’s possible to rank the most relevant matches, allowing developers to find patterns that traditional search might miss. This can be especially useful when refactoring or migrating a system, where developers need to ensure all instances of a specific method or pattern are caught—even those using different libraries or syntactic variations.
For example, when migrating from one identity provider to another, embeddings can help find all occurrences of an HTTP authorization header across a range of different libraries like WebClient or OkHttp3, even if the exact method names are not known upfront.
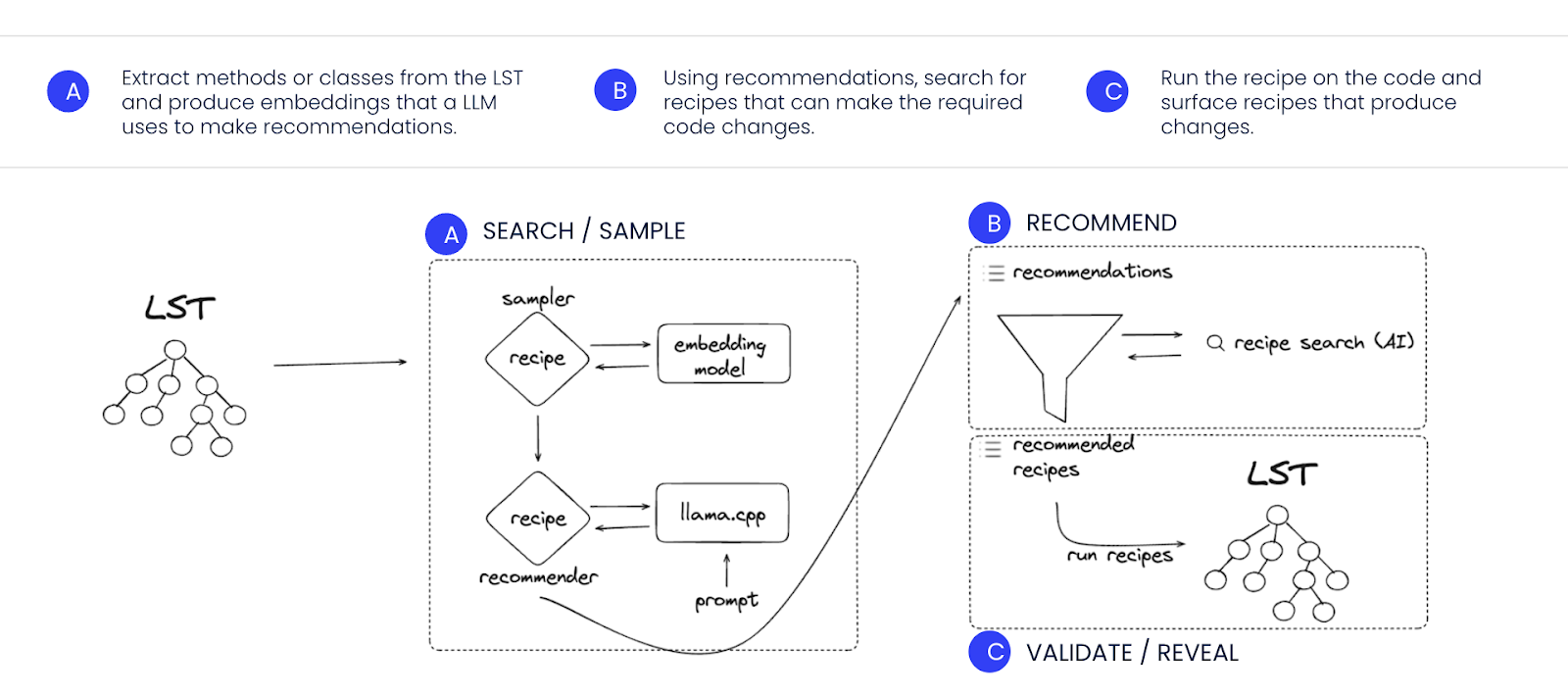
The top-k selection technique further enhances the search process by narrowing the search space to the most relevant candidates, significantly improving search speed and accuracy. The embedding-based approach allows AI models to compare the similarity of method signatures with the query and prioritize results based on this similarity, which is made possible thanks to the information the LSTs contain. By using multiple models in a chain, starting with smaller, faster models and only invoking larger models when necessary, the process stays efficient while maintaining high accuracy. Figure 3 shows the entire process.
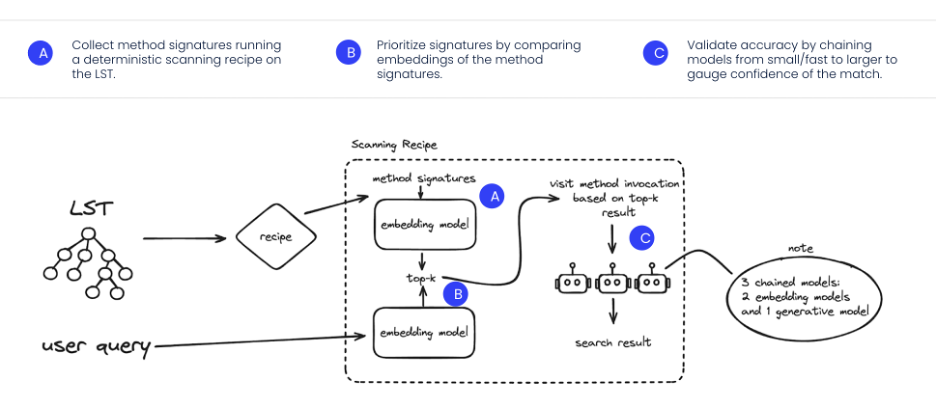
This method avoids brute force searches, which can be inefficient in large repositories, and allows developers to focus on impactful code without having to rely on complete knowledge of the entire codebase. You can learn more about this search use case in our documentation; and if you’re interested in the nuts and bolts of the pipeline, check out this blog.
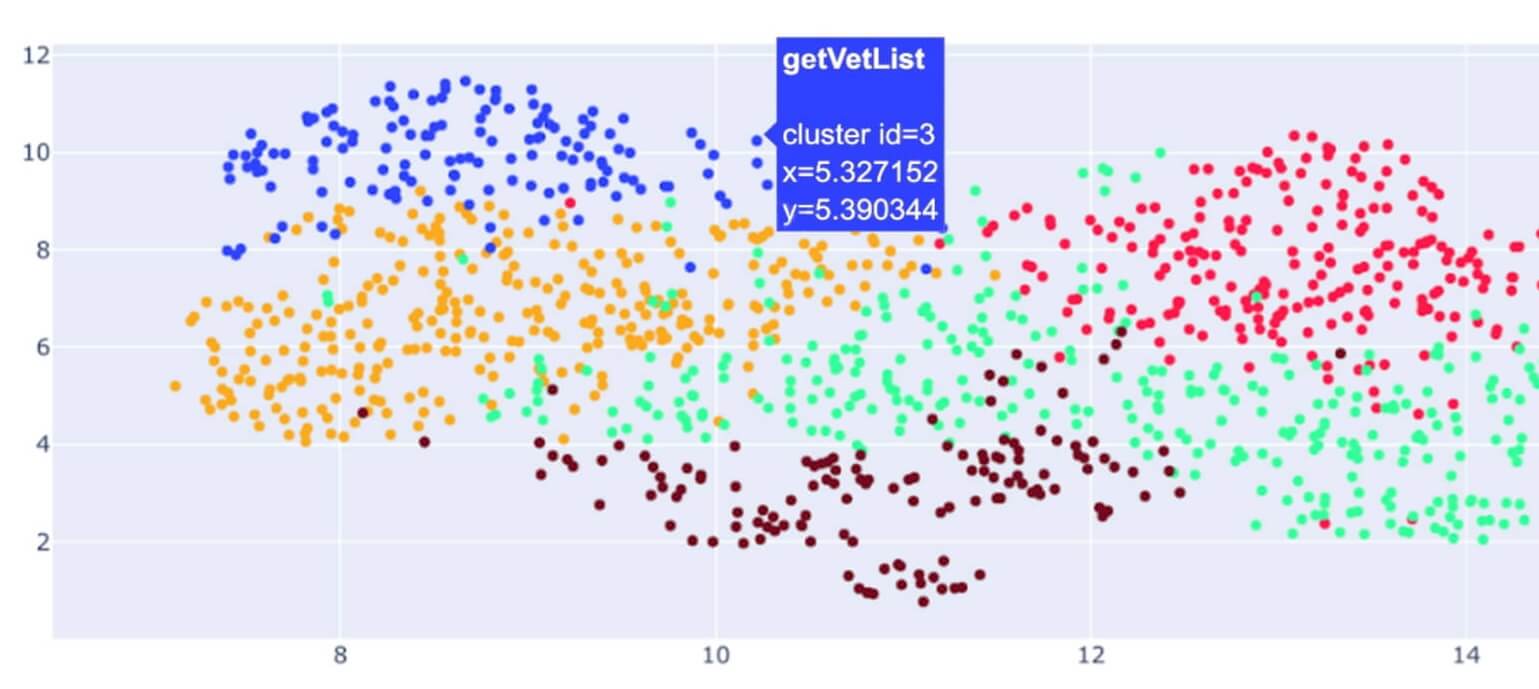
Birds-eye visualization of a codebase
Using AI clustering to gain a high-level overview of your codebase allows developers to visualize and understand how different parts of the codebase are connected. By clustering methods or classes based on their embeddings, you can see which elements are closely related in function and structure, even if they’re spread across multiple repositories in the codebase. This is particularly valuable in large projects, where identifying related methods can be challenging without a tool like this.
For example, a developer could use clustering to spot scattered methods that perform similar tasks, such as file handling, and identify potential refactoring opportunities to improve modularity. Additionally, clustering can help in detecting inconsistencies in method names, like identifying methods named differently but performing the same action, which can lead to cleaner, more standardized code.
The key to this process lies in embeddings, which convert method declarations or classes into numerical representations that capture their features. By calculating the similarity between these embeddings, the clustering process groups related methods or classes together. The resulting visualization shows these relationships in a 2D scatter plot, with dots representing individual methods or classes.
The proximity of dots indicates similarity, allowing developers to quickly understand which areas of the codebase are closely connected. For example, hovering over a cluster of dots might reveal a set of file read, write, or delete operations that could be refactored into a more cohesive structure. This type of high-level visualization is crucial for improving code readability, modularity, and consistency.
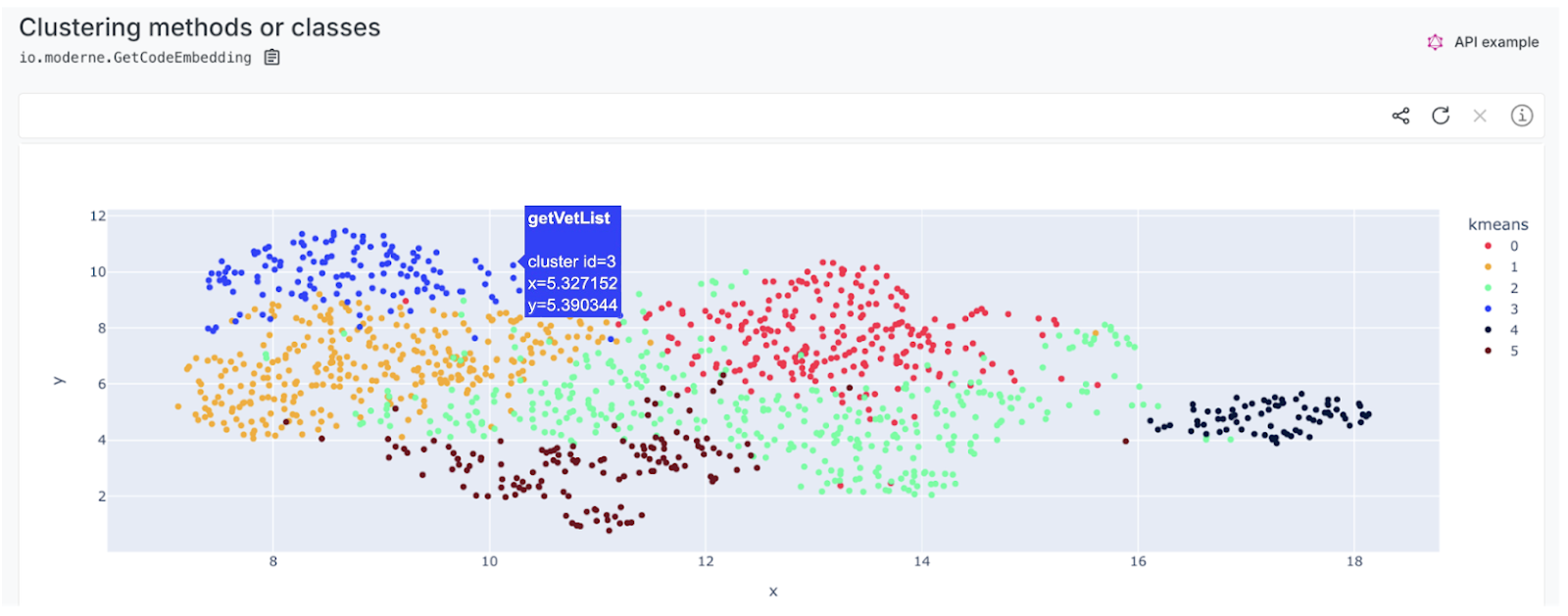
Here’s an example of how to run it on code:
Smart sampling for relevant recommendations
When trying to generate recommendations for recipes to run on a codebase, one of the challenges is ensuring that the recommendations are both relevant and actionable. Simply feeding an AI model random pieces of the code is unlikely to provide meaningful results, as it may overlook key areas or patterns that require attention. The goal is to make smart recommendations tailored to the specific structure and needs of the codebase, such as suggesting modernization fixes or migration steps.
To address this, we leverage clustering to sample the codebase intelligently. Rather than using random sampling, which could miss important sections, we group similar method declarations or code components using embeddings and then sample from those clusters. This approach ensures that the generative model is exposed to a wide variety of code patterns and functionalities, allowing it to produce more comprehensive and accurate recommendations.
By sampling from diverse clusters, the model can generate tailored suggestions that are directly relevant to different parts of the code, increasing the quality of the recommendations and reducing the likelihood of irrelevant or hallucinated output. These suggestions are then matched with safe, tested OpenRewrite recipes, ensuring that only meaningful, actionable recommendations are presented to the user. See the full process in Figure 4.
Faster debugging by clustering build errors
By building LSTs, developers can ensure that automated code analyses and transformations are comprehensive and reliable, making it a foundational step for any large-scale code modification project with Moderne. However, building LSTs across a large number of repositories can sometimes fail due to inconsistent build environments, missing dependencies, or misconfigurations, particularly when using mass-ingest tools to process logs from diverse projects. This is where clustering build logs becomes invaluable for identifying and resolving common issues efficiently.
Clustering build logs is a powerful method for analyzing common build issues across multiple repositories, enabling you to quickly identify recurring patterns and prioritize fixes. Instead of manually reviewing each failure, AI-driven clustering can group similar build errors together based on their content, allowing developers to tackle the most frequent and impactful problems first. For example, if several projects fail due to dependency resolution issues, clustering will group these failures together, helping you spot the most critical root causes quickly. This approach is particularly useful when dealing with large codebases and many repositories, where it can be difficult to keep track of individual issues.
The use of embeddings in clustering enables this method to group together logs that may not be identical but share underlying patterns, such as stack traces or error messages. Embeddings transform log data into numerical vectors that capture the semantic meaning of the errors, allowing similar logs to be grouped even if they aren’t exact matches. This makes it easier to see trends across different projects, such as recurring dependency issues in Maven or Gradle builds. By visualizing these clusters, developers can immediately see which problems are widespread and prioritize those for resolution, streamlining the debugging process and improving overall build reliability.
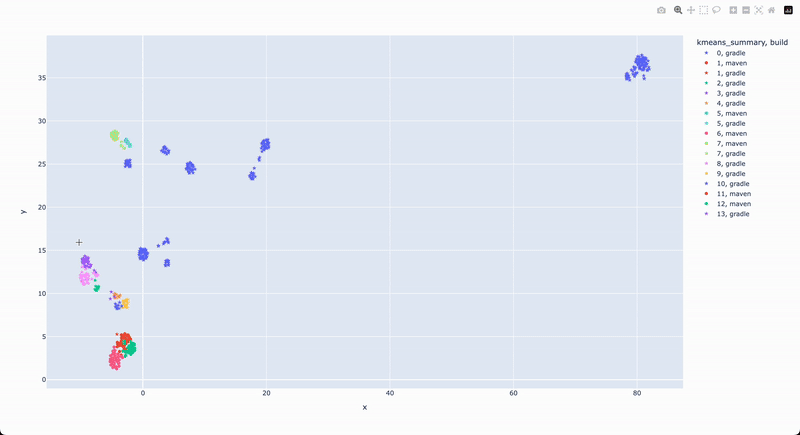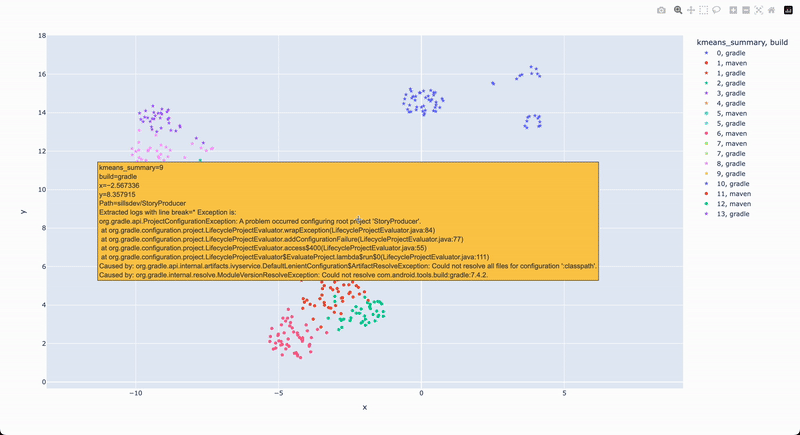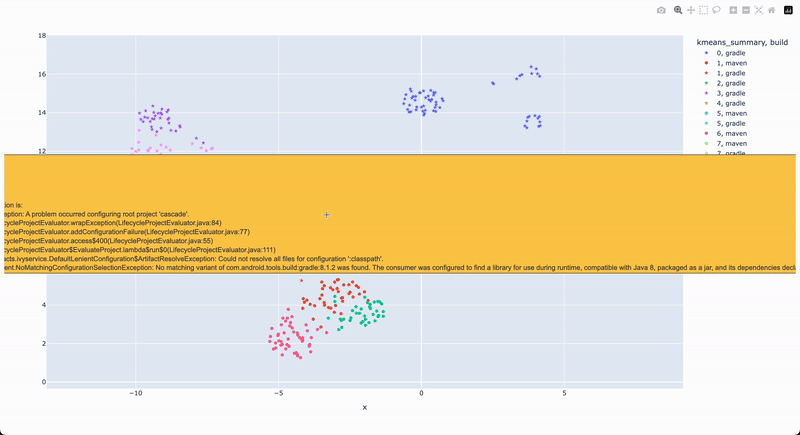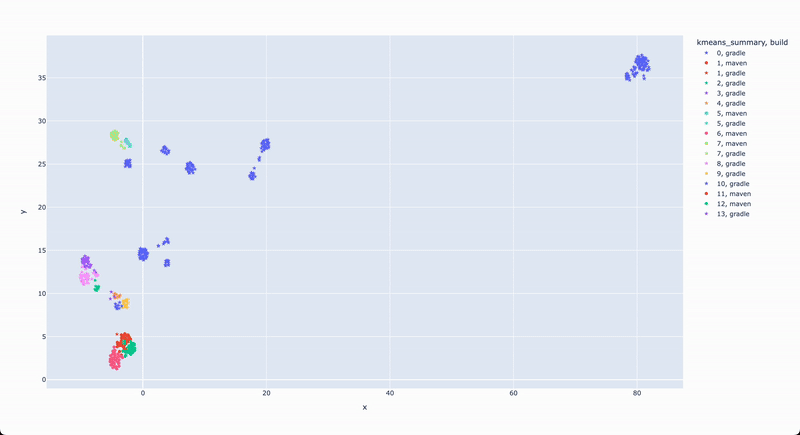
Clustering search results from a recipe run
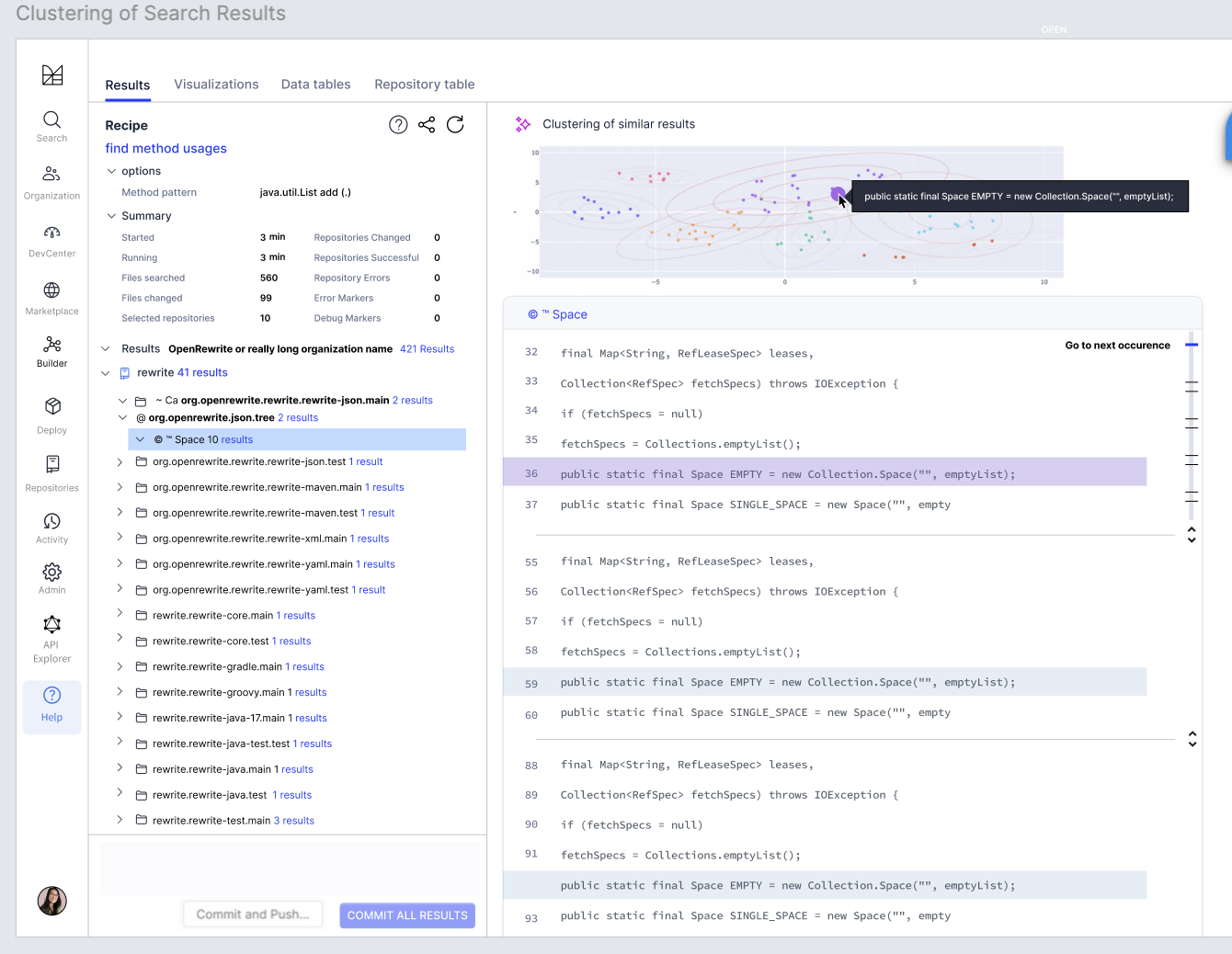
Another useful application of embeddings (currently under development at Moderne) is to provide a way to visualize search results from a recipe run. Whether you’re looking for all the different class declarations that implement a specified type or deprecated methods, it can be more useful to see similar results grouped together rather than navigating the results page by page. Embeddings is the key behind grouping these similar search results together. This is still a work in progress in the Moderne Platform, so stay tuned!
Using embeddings for code with Moderne
Embeddings are a powerful tool that can be used for a multitude of coding tasks—helping organizations develop faster, understand deeper trends, and plan for migrations. The Moderne Platform can fully leverage embeddings with recipes and make them more informative and useful with better code data from the LSTs. To learn more about how you can leverage AI in your large-scale code maintenance and modernization initiatives, contact Moderne.
Related posts


