“The SDLC is a relay race between systems of record and automation.”
Contents
Today I’d love to pull out something I heard years ago from the insightful Pat Johnson. You already know it, but you’ve never heard anybody articulate it so clearly!
My history with the SDLC
My first professional software development job was at Shelter Insurance in Columbia, MO. I inherited the additional duty of “deployer” from my friend Ben Johnson when I joined. “Deployers” were responsible for checking out source code at a particular commit, building it in Eclipse on their local workstations, and manually deploying it. Today, Shelter Insurance is super advanced in its SDLC practices, but such was the era.
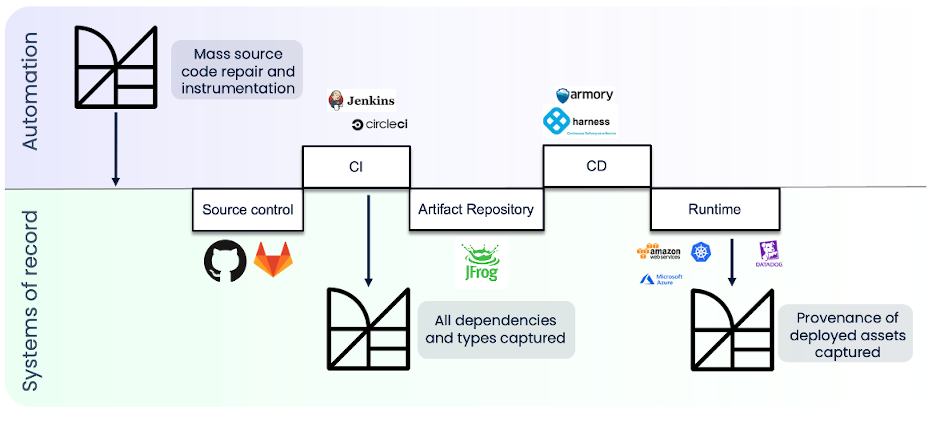
Tooling connects this race in perfect alternation
Wow, times have changed. Along came CI, build tooling, binary integration, artifact repositories, CD, testing automation, application monitoring, etc.
Source control (system of record)
CI (automation)
Artifact repository (system of record)
CD (automation)
Runtime (system of record)
No one company can own the race, nor should they
I’m deeply skeptical of any attempt to “own” the whole race. I think that the SDLC is a “business process of software delivery” (I first heard this from Olga Kundzich). The business processes that are attached to particular tools along this relay race are both complex and entrenched. Yet we crave end-to-end asset visibility. The winner of end-to-end asset visibility will work alongside the SDLC rather than seeking to replace it (though I think Sid Sijbrandij wouldn’t agree).
Related posts


