What is the Lossless Semantic Tree (LST) code model for automated refactoring and analysis?
Contents
Our end-goal at Moderne is to enable development teams to automate source-to-source code transformation at scale and with confidence.
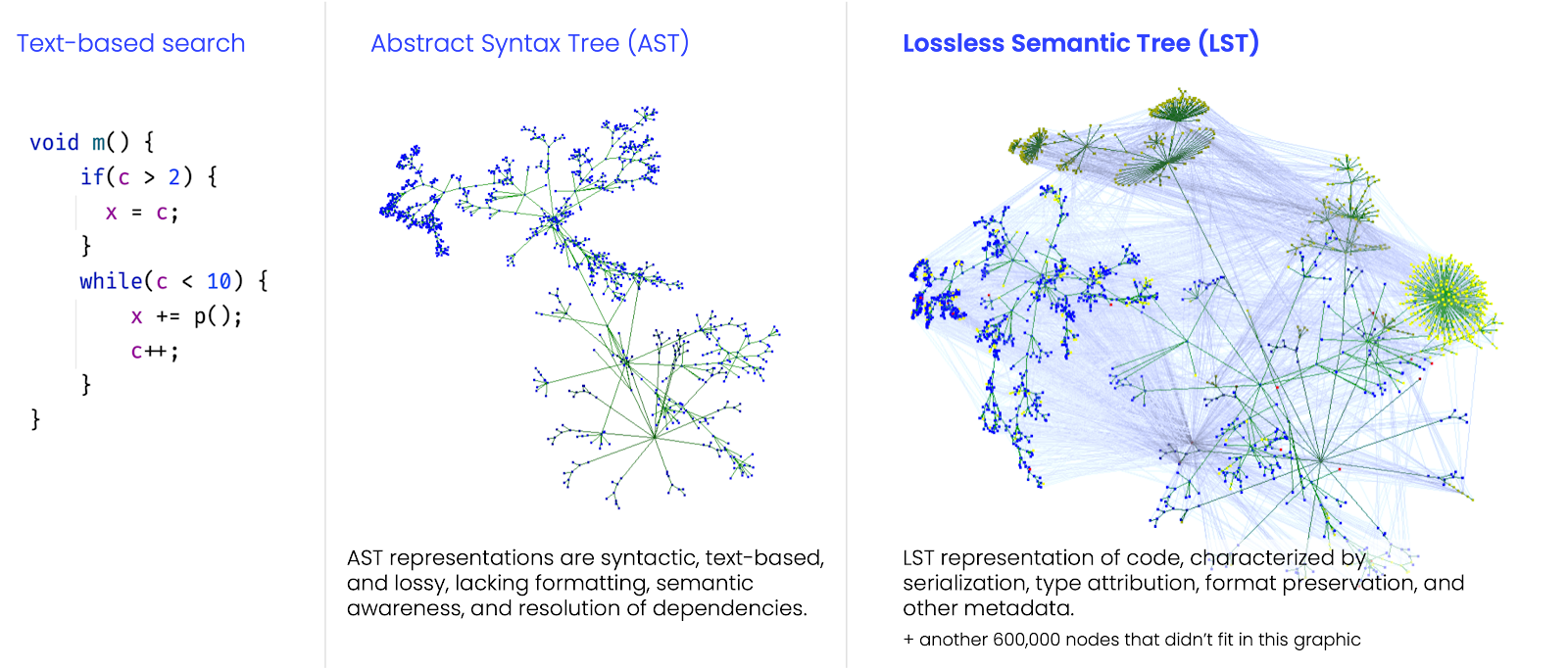
Code scanning tools on the market today enable reporting on issues and vulnerabilities—and now generative AI assistants are available to help remediate and refactor the code in the developer flow. These tools typically search code based on an abstraction or an index of the code, and therefore results can be lossy (or imprecise). It’s also one thing to edit a file with regular expression find and replace or for an AI assistant to change code in a single repo that is then reviewed by the developer, but what if you wanted to change and review code in 1,000s of repos at once? These methods do not scale.
Mass code refactoring—whether that’s migrating frameworks, cleaning up code, or guarding against vulnerabilities—is a multi-point operation that requires accuracy and consistency. It’s about affecting changes across many individual cursor positions in thousands of repositories representing tens or hundreds of millions of lines of code. For this job, a new code representation was needed that would comprehend the full fidelity of a codebase in order to accurately search, analyze, and transform code. This sophisticated code representation, called the Lossless Semantic Tree (LST), was created by Jonathan Schneider, CEO and co-founder of Moderne, as a foundational technology to both OpenRewrite and the Moderne Platform. It’s a technology leap from the common Abstract Syntax Tree (AST), providing rich, semantic-based data including all dependencies (transitive and direct), type information, and formatting—everything needed to search and transform code programmatically—even improving the accuracy of AI models.
What is a Lossless Semantic Tree (LST)?
The LST data model is generated at compilation time and represents the full fidelity of the source code. It’s like a detailed map of your code’s structure and relationships. It helps tools and developers understand and improve code more accurately and safely by preserving all the important details about how the code is organized and how its parts interact.
The LST contains rich semantic information of the code characterized by type attribution, format preservation, and other metadata that is used to implement code analysis and transformation. Specifically, it:
Preserves formatting, including inferring the local and global formatting preferences from observation.
Preserves the entire type awareness (or type attribution) that the compiler possesses in its intermediate representation before producing its final output.
Has higher error-tolerance, designed to handle incomplete type information.
As you can see in the figure, even a pruned representation of the LST creates a very dense tree. A simple snippet of Java code without many binary dependencies can yield an LST containing 8.1 million vertices! With this many nodes and vertices, efficient deduplication is key to the performance of the refactoring engine using the LST. Deduplication is itself a complex process. Even two method invocations against the same method name with the same fully qualified receiver type name and the same arguments could represent two entirely different trees. An example would be when two method invocations are pointed at two different versions of the same binary dependency. Having full type attribution is essential to making accurate remediation decisions. Basically, with LSTs, any dynamically formed query or change of code can be performed without an additional database or indexing of code.
The LST is also the most comprehensive data source for supporting AI in code refactoring and analysis tasks.
How does the Abstract Syntax Tree (AST) compare to the LST?
We store source code as text. Various source code representations exist that help us either compile code and produce executable programs or analyze the code. The AST is one of those representations.
The compiler produces an AST during the syntactic analysis stage, representing the structure of the code. It’s called “abstract” because it does not represent every detail appearing in the actual code syntax. For example, it will omit grouping parentheses or commas separating statements as implicit in the tree structure. ASTs don’t preserve formatting and do not have type awareness.
ASTs are foundational to various code analysis tools, but other abstractions also exist, such as control flow, data flow, and dependency graphs.
This lack of detail and context in these abstract models delivers a lossy code representation for search purposes. For example, when identifying an issue such as Log4Shell or applying logging best practices, a scanning tool will be looking for patterns like Logger. Unfortunately, the AST does not have enough metadata to be able to identify this Logger coming from Log4J or other popular logging libraries. So, it will overreport and have false positives identifying other Logger types, resulting in extra work for developers to examine.
The lack of context in the AST also means that it is not a sufficient base for automatically transforming the source code. The LST, on the other hand, was designed with the goal of transforming the code.
The LST is produced by guiding the compiler through both syntactic and semantic analysis stages, forcing it to produce full type attribution. Then, we go back to source code and scoop up the formatting and other syntax elements discarded on the AST. The resulting LST artifact is a full-fidelity model of the source code.
This rich data enables type-aware semantic search, resulting in 100% accurate matching of patterns, which can greatly reduce the search volume to what’s really important. Additionally, this rich data, including the preservation of code format, enables accurate, automated code refactoring and remediation. Changes can be made to the LST, and then the modified trees can be printed back to source code, matching the local code style.
The importance of style preservation in the LST
In modern enterprises stylistic inconsistency is common—even if an organization has every intention of using a particular style. It is the side effect of many years of evolving best practices (and sometimes new language features). This creates a challenge for automating code remediations and migrations. The LST as a data structure solves for this problem by preserving style so that we can make the most minimal, least destructive diff possible.
When being built, the LST captures all formatting and associates it with syntax elements. From the formatting present on the LST, a style governing the project can then be derived.
For example, the style will know:
If the project use tabs or spaces
If the project use star import formatting
How many types need to be present in a package before it is star-folded
How import statements are grouped together
What the project’s standards are around the use of blank lines between methods, between classes, before the first method, at the end of the file, and so on
The styles themselves are captured on the LST in the form of markers implementing the Style interface. Then, when edits are made to the LST, they are able to use auto-format helpers to shape the edit in a way that looks idiomatically consistent in the context of the codebase where it is being inserted. The same accurate change applied to different projects can look very different.
The Moderne Platform horizontally scaling LSTs
You can think of the Moderne Platform as a scalable refactoring engine that works with LSTs. LSTs are stored outside of local in-memory build tools in your artifact repository of choice. This triggers ingestion into the Moderne Platform, so that the code is available to work on shortly after being compiled.
Unlike OpenRewrite, which produces and operates on an LST in memory, Moderne proprietary IP enables separating the production and storage of LSTs. That means that LSTs can be stored/cached and support multiple searches or code transformations at scale—enabling any query or transformation request to be executed in seconds. Hundreds of millions of lines of code can be operated on simultaneously.
This enables Moderne to be a very effective data warehouse for code—analyzing and transforming multi-language codebases by running OpenRewrite recipes at scale. Recipes encapsulate queries and changes with building blocks for typical operations provided out of the box (such as find or change type). There is no need to learn a new query language for developers. Custom recipes can be developed in the same language as the code being analyzed and transformed. The built-in recipes are consumed via the Moderne Platform using forms with options.
The ability of Moderne to cache LSTs is incredibly useful for custom recipe development as well. A recipe test on a real codebase is condensed from hours to a couple of minutes with Moderne. The fast feedback cycle could be the difference between being able to accomplish a custom migration or not.
LSTs as the most comprehensive data source for AI models
The Moderne Platform offers AI agentic experiences by combining natural language human-computer interaction with tool calling (whereby recipes are tools) to take advantage of the rich LST code data source. This enables experiences such as describing dependencies in use, upgrading frameworks, fixing vulnerabilities, or locating where a piece of business logic is defined (like the location of payment processing code)—across an entire codebase. We’ve found that the more concise, complete, and accurate the data you feed to the model, the fewer hallucinations and better the results, which is critically important for making mass-scale code changes you can trust.
Read the Moderne sponsored O’Reilly book for more information about the full suite of technology behind automated code refactoring and remediation at mass scale. Contact us to see a demo of LSTs in action.
Related posts


