How to use generative AI for automating code remediation at scale

Contents
- Scalable auto-remediation needs rules, not probabilities
- Deterministic automated code refactoring at scale
- The experiment: AI vs. rules-based code refactoring
- The results: Rules-based auto-remediation rules
- The Moderne deep-learning system built with code-trained LLMs
- Mila and Moderne partnership: Innovating with ML for code
Companies have been investing hundreds of thousands of manual hours every year in securing and maintaining their codebases. It’s not uncommon for developers to be inundated with alerts for security, compliance, and quality issues. They have more information about the state of their code than they can process—including a lot of advice about how to fix the issues. In fact, you could say that the flaws are outpacing the fixing at this point.
That’s the crux. While the industry has automated reporting of issues and version bumps of open-source libraries, developers must still do a significant amount of repetitive, manual remediation work to the source code to eliminate vulnerabilities and improve their code.
Now, you might be heartened by the emergence of generative artificial intelligence (AI) solutions that offer coding suggestions to the developer at the cursor. This means your hundreds or thousands of developers are each evaluating the accuracy of AI-assisted code changes with every insertion. Is the AI hallucinating? Did it introduce bugs and insecurities? Then the developer must accept, modify, or reject the insertion before moving forward with their development.
Mass code refactoring, however, is a multi-point operation that requires accuracy and consistency. It’s about affecting changes across many individual cursor positions in thousands of repositories representing tens or hundreds of millions of lines of code. Whether you’re migrating frameworks or guarding against vulnerabilities, this requires coordination and tracking of activities.
In this use case, a suggestive system doesn’t scale to the number of humans needed to perform quality control. With current AI approaches, you could end up with inconsistent, error-ridden, and still very developer-time-intensive code maintenance.
To solve this problem, Moderne has developed a novel approach to automated code remediation at scale that uses deep learning. But before we get to that, let’s cover why the code remediation task needs more than an in-line AI assistant.
In this article, you’ll learn:
Why scalable auto-remediation needs rules, not probabilities
How automated refactoring compares to generative AI in an experiment
What Moderne’s deep learning AI system is all about
How Moderne is partnering with the Mila_ - _Quebec AI Institute
Scalable auto-remediation needs rules, not probabilities
Code remediation is a different type of development task than code authorship. Remediations require deterministic changes. The changes are enumerable—there is a right answer—that can be expressed as rules. They can also assume that code is in a working state to begin with, and thus produce a one-to-one correspondence before and after the fixes.
Based on these guidelines, Moderne has developed a rules-based refactoring engine for code transformations—which is the heart of automated remediation. With this engine, we are able to assemble rules that are much more complex, progressively encapsulating lower building blocks while still being 100% accurate. For example, there aren’t multiple valid branches to implement remediations like upgrading from JUnit 4 to 5. The requirements are immediately enumerable and can be built into rules that are automated.
The remediation rules are codified as recipes—actual programs that prescribe how to search and transform source code. There are currently over 1,000 open source recipes as part of the OpenRewrite project, which is a foundational element of the Moderne platform. The OpenRewrite community is dedicated to making software seamless to update and continuously secure.
Many building-block recipes exist, such as find method, change method, find transitive dependency, upgrade dependency, and exclude dependency. These recipes in turn can be composed into more complex recipes by grouping them into a composite recipe. When the building blocks are not enough, a recipe can be written as a program in the same language as the code we want to transform—encapsulating complex logic with the full expressiveness of the language already familiar to developers.
A recipe becomes your software cookie cutter, able to make the same exact change anywhere it’s relevant in your code. A cookie cutter is designed and validated once by the baker, and then used at scale to make completely accurate cookies. This is much more efficient and accurate than relying on manual or AI-assisted code changes within the developer flow, which would offer different and possibly inaccurate changes for the same fix. In our cookie analogy, you’d end up with many different looking cookies versus uniform, perfectly delicious cookies.
What’s more, developers learn to trust rules-based systems, whether it’s IDE autocomplete or the more comprehensive changes provided through recipes, because of their consistent accuracy. And once trust is established, you can work even faster.
Deterministic automated code refactoring at scale
More than saying ‘take our word for it,’ we wanted to show you the efficiency and accuracy of a rules-based model leveraging OpenRewrite recipes against a generative AI model in a remediation use case.
To do this, we set up a small experiment that stood up rules-based auto-remediation against OpenAI’s ChatGPT and StarChat-β large language models (LLMs), as well as manual human efforts.
The experiment: AI vs. rules-based code refactoring
For this experiment, we wanted to employ a use case that necessitated more intricate search patterns beyond simply locating an API name. We chose a SonarQube static analysis rule (RSPEC-4524) that addresses the position of the default clause in a switch statement. In this pattern, it is more readable for the default clause to appear last, but this is not always done.
We asked each of the actors in the experiment to find all instances of “default not being last” and correct them. This is how we performed the experiment with each actor:
**Rules-based auto-remediation: **Using the Moderne platform, we ran the OpenRewrite recipe org.openrewrite.staticanalysis.DefaultComesLast on four public repositories that we knew contained examples of a switch statement where the default case was not last. The platform uses an AWS m6a.xlarge instance to run this OpenRewrite recipe to apply changes to the file. Moderne’s platform also keeps track of the performance of the recipe and provides a CSV file that contains the time it took to find and apply the change if needed for each file.
**Generative AI tools: **Using ChatGPT and StarChat-β, we appended the query “Repeat the code making sure that any default case is in the last clause of a switch statement: \n” in front of the content of a file. This AI process was performed on four Java files from three distinct repositories, each containing a single instance where the default clause was not in the last position. Since ChatGPT and StarChat-β both are non-deterministic in the current experiment setup, we tested each file five times each. We then graded each output based on accuracy (i.e., was the change correct) and completeness (i.e., is everything else present). Files without an incorrect default statement were excluded from testing, as our focus was on highlighting the disparities between these methods.
**Humans: **We wanted to offer insight into how the same tasks would be performed if done by a developer by hand. Instead of a real-time estimate, we used SonarQube estimates that say fixing the issue “default clauses should be first or last” would take 5-minutes per instance. As for the accuracy, we cannot ignore the possibility of a human mistake from doing repetitive tedious work.
The results: Rules-based auto-remediation rules
In our focused evaluation, OpenRewrite recipes running in the Moderne platform demonstrated superior speed when applying changes to a file compared to other methods. Furthermore, the recipes showcased deterministic behavior, achieving a remarkable 100% accuracy in implementing the desired modifications. ChatGPT, overall, performed slightly better than StarChat-β, although both models exhibited some incorrect instances.
Notably, in the majority of these cases, no changes were actually applied to the code. However, there was one occurrence where ChatGPT responded without providing code alterations, incorrectly indicating that no changes were necessary due to the absence of a switch statement with the default clause in the last position. This behavior may be attributed to a higher temperature setting, influencing the model’s output generation. There is quite a disparity in the time it takes to apply the changes to the files.
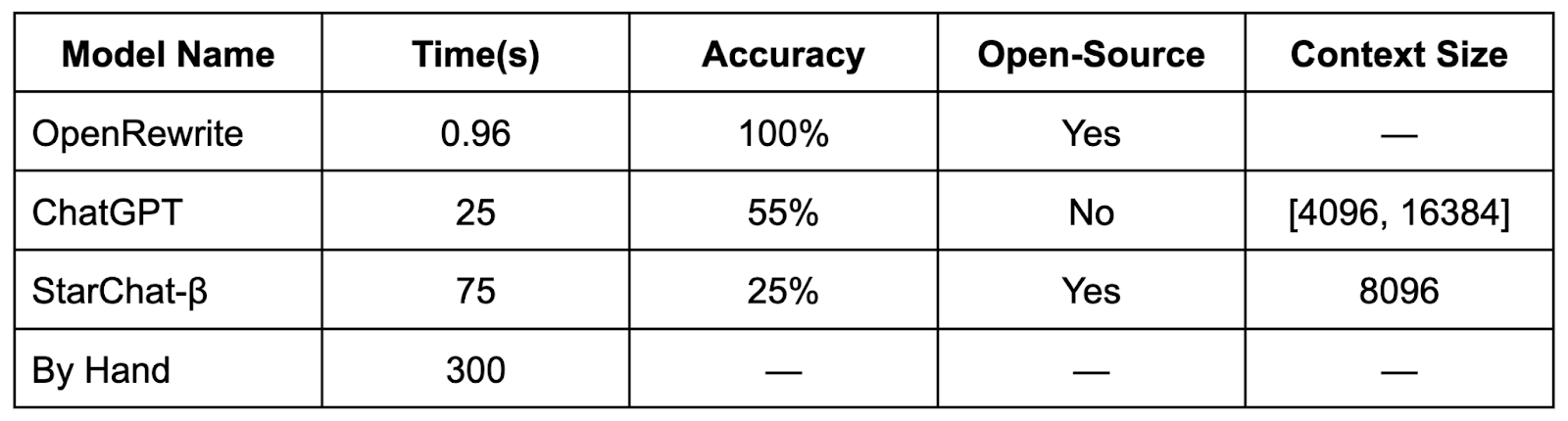
When you think about the auto-remediation effort with Moderne, a recipe is created and validated once, then it can run to completion in minutes, fixing code across thousands of points. If you imagine developers making the same remediation in thousands of places with individual AI support, we’re talking days to weeks of time. You can see why the Moderne approach to remediation is so efficient and cost-effective for modern codebases.
One thing of note that this experiment confirmed for us is that AI is more successful (i.e., accurate) if the issues are identified first then provided to the AI to focus the work. As an anecdote, the AI performed better when only given the code snippet that needed to be changed.
None of this is meant to discount the power and potential of AI for development organizations. Rather, we want to share a better way to use it. The Moderne platform is ideally suited for applying AI to coding use cases.
The Moderne deep-learning system built with code-trained LLMs
Moderne is establishing the most effective way for humans and AI to maintain and secure source code together.
To start, we have implemented the BigCode project’s StarCoder LLM to help inform and speed auto-remediations. The StarCoder model has been trained on code from GitHub, including code from more than 80 programming languages, Git commits, GitHub issues, and Jupyter notebooks. With a context length of over 8,000 tokens, the StarCoder model is powerful—able to consider more comprehensive information and provide more accurate and contextually relevant outputs than any other open LLM (according to the project).
Moderne has further fine-tuned the model for the specific task of programming code search and transformation recipes. This enables the model to be more efficient and improve its accuracy for this more narrow use case.
The Moderne deep learning system as shown in Figure 1 is offered as part of our SOC2 compliant, secure SaaS platform. The platform hosts the StarCoder model locally on an organization’s private SaaS instance (a unique model for each customer). This means that the platform that already ingests the full fidelity of your codebase in the form of lossless semantic trees (LSTs) can provide a light-weight way to leverage an LLM with your code.
Your private code doesn’t leave the Moderne environment, and it will never be used for training the large language models we use.
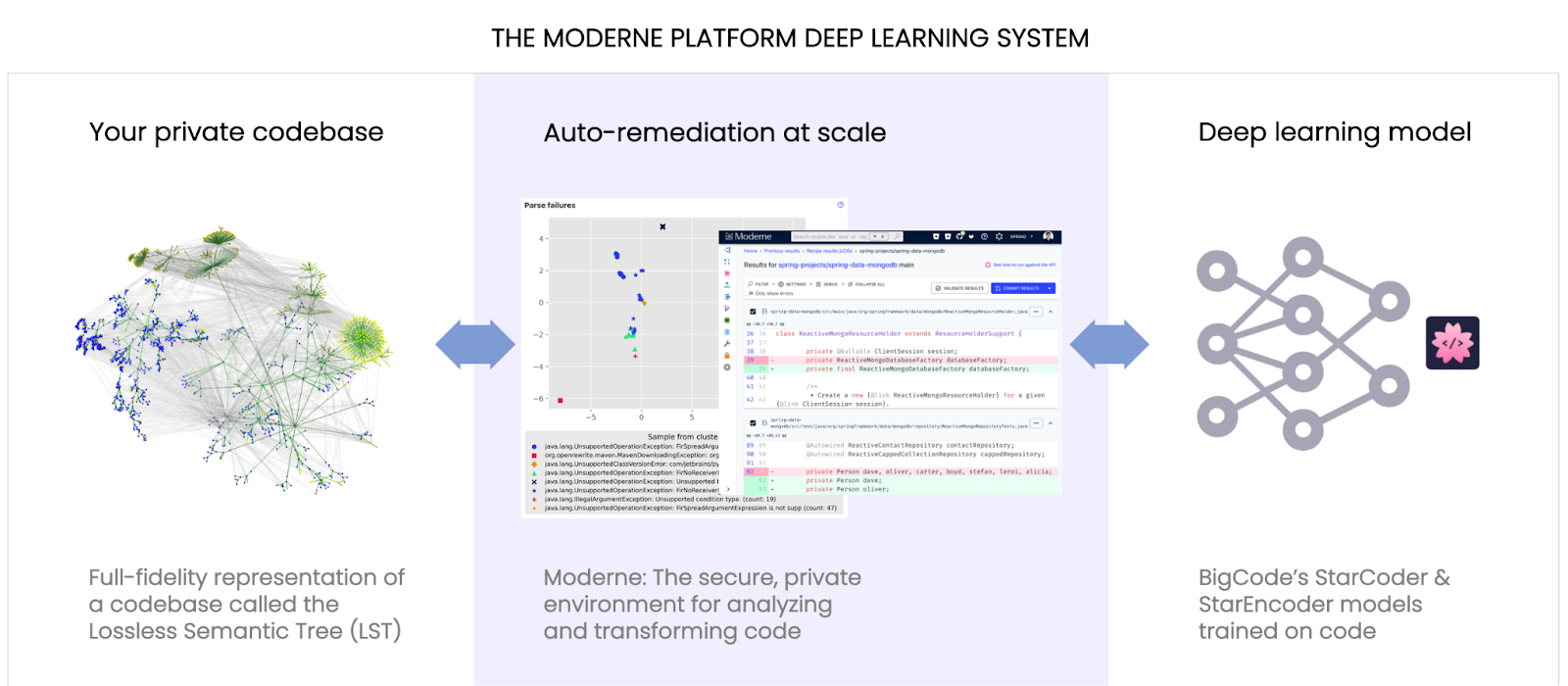
At the moment, Moderne is focused on two significant use cases for AI for maintaining and securing the modern codebase.
First, Moderne is using AI to assist in analyzing aggregated code to provide insights and actions for development teams. We are able to extract meaningful representation of the code, called embeddings, and use the embeddings in downstream tasks such as feature finding, clustering, and finding code similarities and duplications. One of the first downstream tasks we tackled was clustering error messages to prioritize types of errors worth tackling first. This is available in the Moderne platform today.
Second, while auto-remediation with OpenRewrite recipes is the most effective way to fix source code, recipes must initially be created by developers who could use an assist from deep learning. The Moderne platform can use AI to enhance and speed recipe authorship, resulting in 100% accurate code changes. In fact, recipe authorship is a perfect use case for generative AI—with well-defined parameters and well-tested results before put into mass use.
Both of these areas are full of possibilities, and we’ll be covering more of our deep learning research and work in upcoming blogs. As LLMs improve, we’ll also be able to incorporate those newer models as part of our deep learning system. The possibilities for your code are extraordinary.
Watch our webinar to learn more about Moderne and the deep learning AI technology at work behind the scenes.
Mila and Moderne partnership: Innovating with ML for code
To stay at the forefront of the rapidly moving AI tech space, Moderne is pleased to partner with Mila, the world’s largest academic research center for deep learning. Located in the heart of Quebec’s AI ecosystem, Mila is a community of more than 1,000 researchers specializing in machine learning and dedicated to scientific excellence and innovation. Moderne will be co-leading the ML4Code reading group, as well as continuously engaging in research with collaborators to remain updated with the latest findings. Learn more about the Mila and Moderne partnership in our press release.
Contact Moderne to learn more about using deep learning AI to analyze and transform your code.
Related posts


