Deploying AI LLMs on CPUs: Navigating efficiency and scalability

Contents
- GPU vs CPU: Choosing the best processor for AI LLMs
- Challenging the norm: CPUs for LLM deployment
- Optimizing LLM deployment on CPUs in the Moderne Platform
- Implementing LLMs with a sidecar architecture
- Choosing the right AI models for the job
- Deploying AI models on CPUs
- A note on how token size impacts latency
- CPU acceleration techniques for LLMs
- Case Study: LLM-backed recipe recommendations
- Living in the AI jungle
In the rapidly evolving world of artificial intelligence, deploying large language models (LLMs) efficiently is a cornerstone for businesses aiming to integrate AI into their operations without incurring excessive costs or compromising on performance. Moderne’s journey into deploying LLMs on CPU infrastructure sheds light on the nuanced approach needed to navigate the challenges and leverage the potential of existing resources.
In this article, we’ll discuss our evaluation of GPU versus CPU for our AI use cases and why we chose to challenge the prevalent belief that GPUs are indispensable for deploying LLMs. We’ll also share the innovative strategies and technical adjustments we’ve adopted to optimize LLM deployment solely on CPU instances in the Moderne Platform.
GPU vs CPU: Choosing the best processor for AI LLMs
The common industry trend leans towards deploying LLMs on GPUs for their parallelizing capabilities. However, the phase of the LLM—training or deployment—can impact your choice of processor.
GPUs are particularly advantageous for training LLMs—primarily due to their capacity to efficiently manage the computational demands of gradient tracking, a fundamental aspect of neural network learning. For training, even if training a smaller 7b parameters model, a lot of computational power is needed. Indeed, to train Meta’s Llama with 7b parameters, it took 82,432 GPU hours. Training such a large model on a CPU would be impractical. It’s much more suitable to leverage the parallelization capabilities of GPUs for models like transformers, which are inherently designed for parallel processing.
However, choosing CPUs for LLM deployment can be quite advantageous, particularly since even lower-tier CPUs frequently come with more random access memory (RAM) compared to their GPU counterparts. This is useful because more RAM means more space for a model. Moreover, CPU instances are substantially more cost-effective than GPU ones, which is a growing concern for users and operators alike. Although a GPU-hosted model may operate more quickly in terms of tokens per second, accommodating the same model might necessitate a larger, and therefore more expensive, GPU.
While training models on GPUs is indeed necessary, we believe that deploying them on CPUs can be a valid and even beneficial option in many cases.
Challenging the norm: CPUs for LLM deployment
As we set out to integrate AI into the Moderne Platform, we needed an LLM implementation that could operate within the sovereignty of our platform, scale to meet the needs of multi-repository refactoring work, and be very cost-effective.
The nature of the Moderne Platform infrastructure, operating within air-gapped environments, inherently precludes the feasibility of making external API requests. Furthermore, these external services impose fees based on usage (e.g., per token), which could pose significant scalability challenges. Our platform, however, is designed with scalability at its core, enabling us to fully exploit the advantages of LLMs by self-hosting on our pre-established systems. This approach ensures unrestricted usage without the constraints imposed by external usage fees, bolstering our operational flexibility and cost-effectiveness.
In our early explorations, we had to determine if CPUs alone could meet the operational needs of the LLMs we would want to deploy. We rigorously tested the limits of CPU processing power, focusing on generation speed, a factor potentially constrained by the choice between CPU and GPU resources.
Through this process, we illuminated a path forward that questions the status quo, demonstrating that CPUs, when optimized, can indeed support the deployment of large language models effectively. Instead of relying on GPUs, we emphasize optimizing the capabilities of CPUs, striking a balance between affordability and performance while ensuring our service quality remains high.
Read on to learn more about our implementation.
Optimizing LLM deployment on CPUs in the Moderne Platform
Deploying AI models always comes with its own set of challenges, and deploying LLMs on CPU was no exception. We had to navigate deploying LLMs alongside Java processes, finding the right models and techniques for the task at hand, minimizing the latency, and building the environments with the right configurations.
Implementing LLMs with a sidecar architecture
Within the Moderne Platform, code transformation and analysis happens by running recipes (or programs) on the lossless semantic tree (LST) representation of a codebase, which is a full-fidelity model of the code that includes type attribution and dependencies. When we add AI to this system to augment rules-based refactoring work, we leverage your own codebases (i.e., aggregated LSTs) and provide the results to the LLM for its query or generation. We can then validate the LLM output with our accurate refactoring system.
The LST essentially serves as a powerful retrieval augmented generation (RAG) engine, providing highly relevant context to the LLMs for understanding and modifying specific code. It’s similar to what embeddings do for natural language text, but enables the models to be more efficient and accurate.
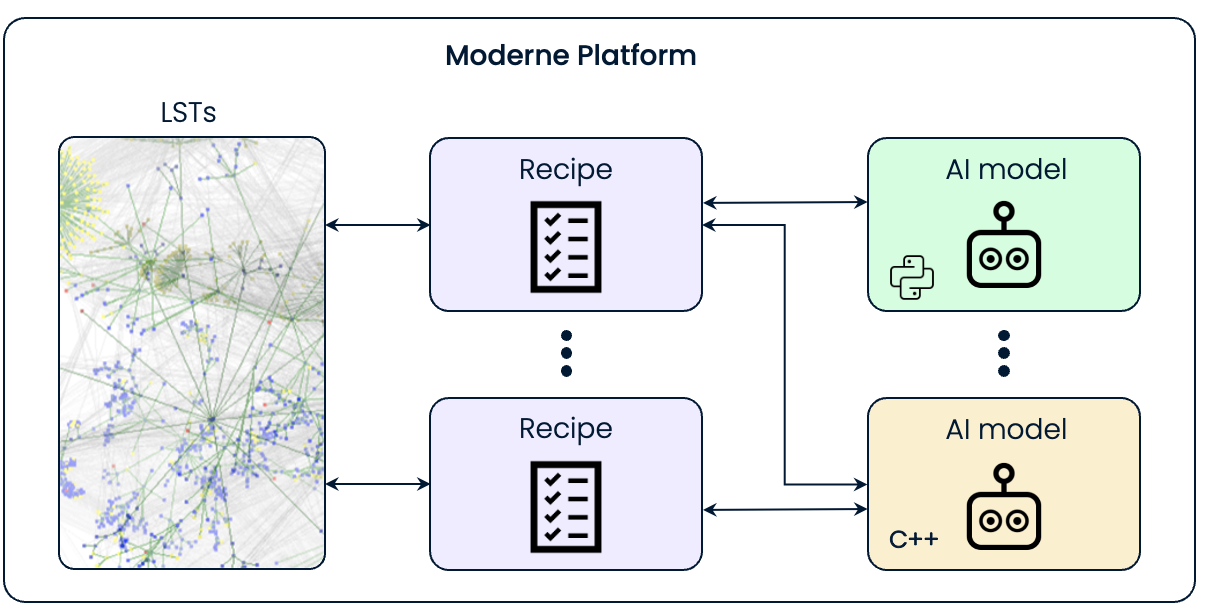
To bridge the gap between our existing Java processes and AI models, we’ve implemented a sidecar architecture as shown in Figure 1. The sidecar model facilitates communication between our main applications and the LLMs, ensuring that AI capabilities are an integrated part of our service offerings without requiring significant changes to our existing infrastructure. The models can be used as necessary by the recipes.
This setup allows us to maintain a seamless operation across the same infrastructure for each Moderne Platform private tenant.
Choosing the right AI models for the job
While the allure of generalist models is undeniable for applications like chatbots, we advocate for a more tailored approach. The philosophy of “using a butter knife instead of a chainsaw to butter a toast” guides us in selecting and optimizing smaller, more specialized models.
Numerous models are available as open-source with flexible licenses for immediate download and use. However, not every model is suitable for all tasks, making it crucial to determine the most appropriate model for your needs. Although the vast selection of models may initially seem overwhelming, we recommend looking at various benchmarks that resemble your task. Huggingface hosts various leaderboards such as for generation models and for embedding models. For example, when using a generative language model for a chatbot-type task, we recommend to use a model that has been either been fine tuned with RLHF or with an instruction dataset. If you are using the model for completion, it is better to not use one of those finetuned models.
While leaderboards offer valuable insights into various models, it’s crucial to recognize that the scores presented might not accurately represent the true capabilities of the models. This discrepancy arises primarily from two factors:
Benchmarking is just one metric, similar to how a student’s test score may not fully capture their knowledge or skills.
**Data leakage can occur **where a model may have been inadvertently trained on the test dataset, enabling the model to artificially appear to perform better.
Deploying AI models on CPUs
Once you have a few candidate models for your task at hand, you can move on to finding a library or framework to deploy them, as well as add techniques to optimize them further:
Framework: Your choice of framework will be influenced by multiple things: simplicity of library, features (such as servers, chaining, batching, or metrics), speed, and which model architecture they support. A few libraries come to mind: Langchain, vLLM, llama.cpp (and its bindings in multiple programming languages), and Hugging Face. Not every framework is suitable for every scenario. It’s essential to understand the capabilities of each framework and determine how they align with your specific needs.
Library features: Additionally, a useful feature to look out for in a framework is the ability to compile quantized models. A quantized model is a version of a machine learning model that has been modified to use lower precision (such as 8-bit integers instead of floating-point numbers) for its calculations and data storage. This reduction in precision helps decrease the model’s size and speeds up its operation. See this documentation for more information.
Additional techniques: We have also found that by incorporating techniques such as retrieval, we ensure that these models are perfectly suited to our needs, providing efficient and effective solutions without the overhead of larger, more complex systems. Optimizing for efficiency involves strategic thinking to reduce unnecessary computational work. For example, in a retrieval task, employing several models arranged from the least to the most computationally demanding can be effective. This strategy leverages less accurate, but cheaper models to handle simpler tasks within the pipeline.
A note on how token size impacts latency
When deploying LLMs, it’s important to consider the impact of token length on response times. The latency increases quadratically with the length of the input or anticipated output due to the attention mechanism integral to transformers, the architecture on which LLMs are built. This effect is observed on both CPUs and GPUs. Figure 2 is a demonstrative example showing the relationship between input token length and latency.
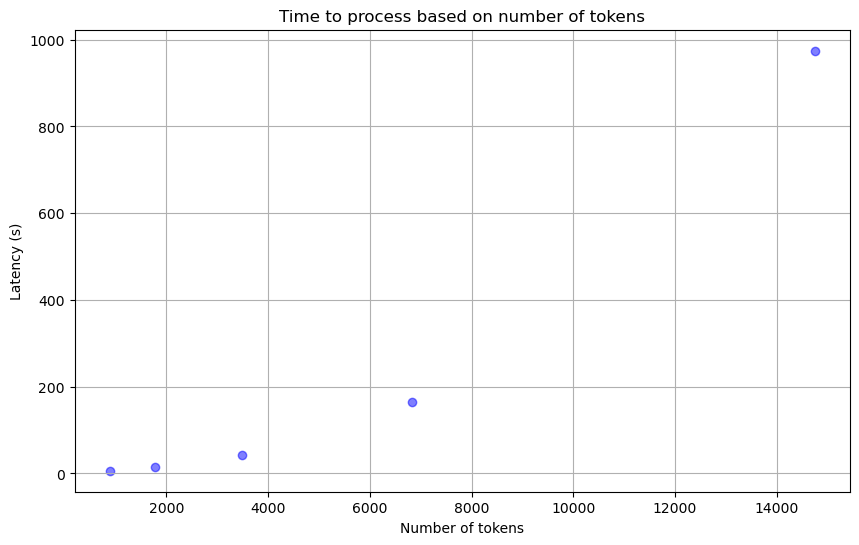
Understanding this impact can guide you in structuring your input text efficiently, avoiding the submission of dense, lengthy texts to the model, which is not ideal. Minimizing input length allows for efficient utilization of LLMs without significantly impacting processing speed.
CPU acceleration techniques for LLMs
Deploying LLMs on CPUs presents its own set of challenges, notably the increased latency compared to GPUs and the lack of libraries optimized for CPU acceleration. These obstacles necessitate a strategic approach to deployment, focusing on both the selection of appropriate models and the optimization of our infrastructure.
To mitigate the inherent disadvantages of CPUs, we employ several acceleration techniques, including Advanced Vector Extensions (AVX) among others. These techniques are crucial for enhancing the performance of our models, making them more viable for CPU deployment. However, the effectiveness of these optimizations is highly dependent on the specific instances used, which introduces additional complexity in our deployment process.
A unique challenge we encountered involved the dependency building process for a generative LLM. Our images were built on GitHub’s servers, which inadvertently tailored them to the CPU flags of those instances. By shifting to compile dependencies on the target instance using ‘make’ at deployment, we ensure that our models are fully optimized for the specific CPU architecture they will run on, enhancing efficiency and performance.
If you do not do so, you might get an error message ‘illegal instructions’ which means the process is attempting to run a pre-compiled function with instructions that the CPU is unable to perform. When running LLMs these errors tend to come from AVX, AVX2 or the more recent AVX512. While most CPUs have AVX and AVX2, older CPUs don’t all have AVX512.
Case Study: LLM-backed recipe recommendations
Let’s put all this together in practice. We wanted to leverage LLMs to generate recommendations for recipes tailored for a particular codebase. Our workflow went as follow:
Evaluate which generative LLM to use for recommendations
Evaluate a sampling strategy using an embedding model
Evaluate which library to use for deploying the recommendations
Build a pipeline for all the steps together
For the first step, we tried a couple different smaller models (~around 7b parameters) such as CodeLlama, Zephyr and Mistral. We landed on an instruct-finetuned CodeLlama as the model better suited for our task. We utilize a quantized version of the model which is compiled by TheBloke, which enhances speed and reduces the space required.
For the second step, we use BAAI’s embedding model bge-small-en-v1.5. We frequently use this model for embedding because it’s a compact model.
For the third step, we decided to deploy the generative model using llama.cpp, a library to deploy LLMs using C++. The library, building upon the quantized model, facilitates rapid inference.
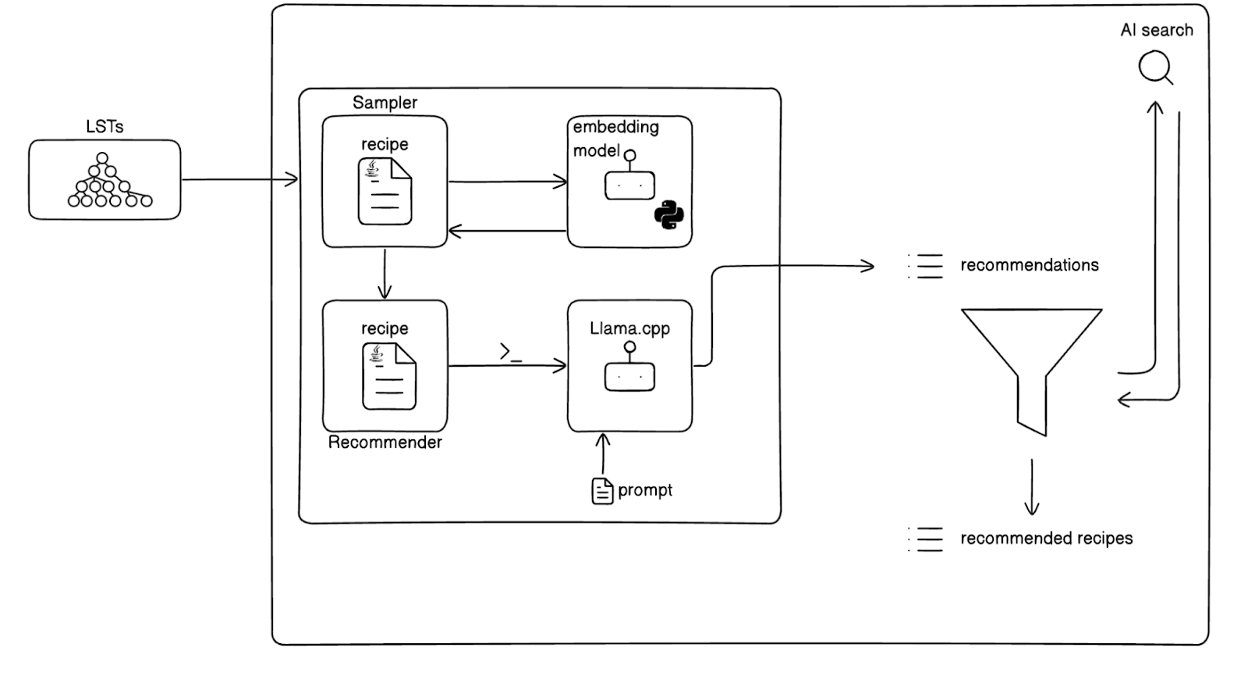
Finally, our pipeline is outlined as follows and depicted in Figure 3.
Initially, there’s a sampling phase that utilizes embeddings from different sections of the codebase. We compute the embeddings by running a recipe that walks through the LST code artifact and computes the embedding on the relevant parts of the code. LSTs enable us to navigate specifically to different parts of the code, such as method definitions, method invocations, or even just comments—elements that a LLM might overlook boundaries for.
By clustering these sections based on their embeddings and then sampling from these clusters, we ensure a diverse selection. Following this, we employ CodeLlama to generate suggestions, and ultimately, we search for recipes that fulfill these recommendations. The search component of our pipeline employs the same search technology as our platform, details of which are available on our blog. A longer blog on this new feature will come out soon once this is fully deployed on our DevCenter, so keep an eye out!
Living in the AI jungle
The deployment of LLMs on CPUs, while challenging, has proven to be a journey of innovation and adaptation. Through strategic choices in model selection, optimization techniques, and smart deployment practices, we have successfully navigated the complexities of CPU-based deployment. Our experience underscores the importance of a tailored approach, leveraging existing resources to their fullest potential while maintaining the flexibility to adapt to the unique demands of each deployment scenario.
As we continue to refine our methods, the lessons learned pave the way for more efficient and scalable AI integrations in CPU-dominant environments. If there is one takeaway, it’s to challenge the conception that you need a GPU for deploying AI in your ecosystem. Much like the inspiring narrative in “The Soul of a New Machine,” confronting and rethinking what’s considered standard and achievable can lead to surpassing expectations and driving innovation.
Contact Moderne to learn more about leveraging AI for mass-scale code refactoring and analysis.
Related posts


