How Moderne engineering built a fast, secure, and cost-effective AI search to assist automated code refactoring

Contents
- Moderne Platform search: Situation analysis
- Building with AI embeddings: Fast and economical for search
- Selecting the right embedding model for the job
- Selecting the vector database for storing recipe embeddings
- Focusing the input to the embedding model
- The “just right” retrieving technique
- Testing our AI-based search techniques
- Establishing test search queries
- AI-based search test results
- Adding reranking to finesse AI search results
- Deploying the AI-powered search on the Moderne Platform
- On to our next AI developments
The power of the Moderne Platform is that it can run thousands of code refactoring and analysis recipes from the OpenRewrite ecosystem across your entire codebase. These recipes automate actions such as updating vulnerable dependencies, migrating frameworks, fixing the OWASP top ten, performing impact analyses, and tracking third-party licenses.
Navigating through the wealth of capabilities in these community-driven recipes was a challenge for our users, though, and needed to be addressed.
We needed a technique that could more flexibly search based on concepts instead of exact words, so we turned to building a search function based on artificial intelligence (AI). This function needed to be fast and operationally inexpensive (both in time and financially), allowing us to scale as the recipe catalog grows. We also wanted to use an open-source solution where we had more control over security for air-gapped and restricted environments, so using OpenAI’s API was out of the question.
Spoiler alert! Check out the final deployed AI-enabled search function in our video below, then read on to learn more about the development of this function, including our exploration of AI technologies and techniques best suited for search.
Moderne Platform search: Situation analysis
Recipes are programs that drive code search and transformation operations in the Moderne Platform. They can be simple operations or made up of many different recipes, called composite recipes. Each recipe includes a name and a short description that can be leveraged for discovery.
The existing Moderne text-based search, using a Lucene-based index, relied too much on the user knowing the exact terms in the recipe name. In addition, many terms can be used to describe the same thing, which complicates the search even more for the user. For example, the query of ‘new java’ would not return the latest Java 21 migration recipe.
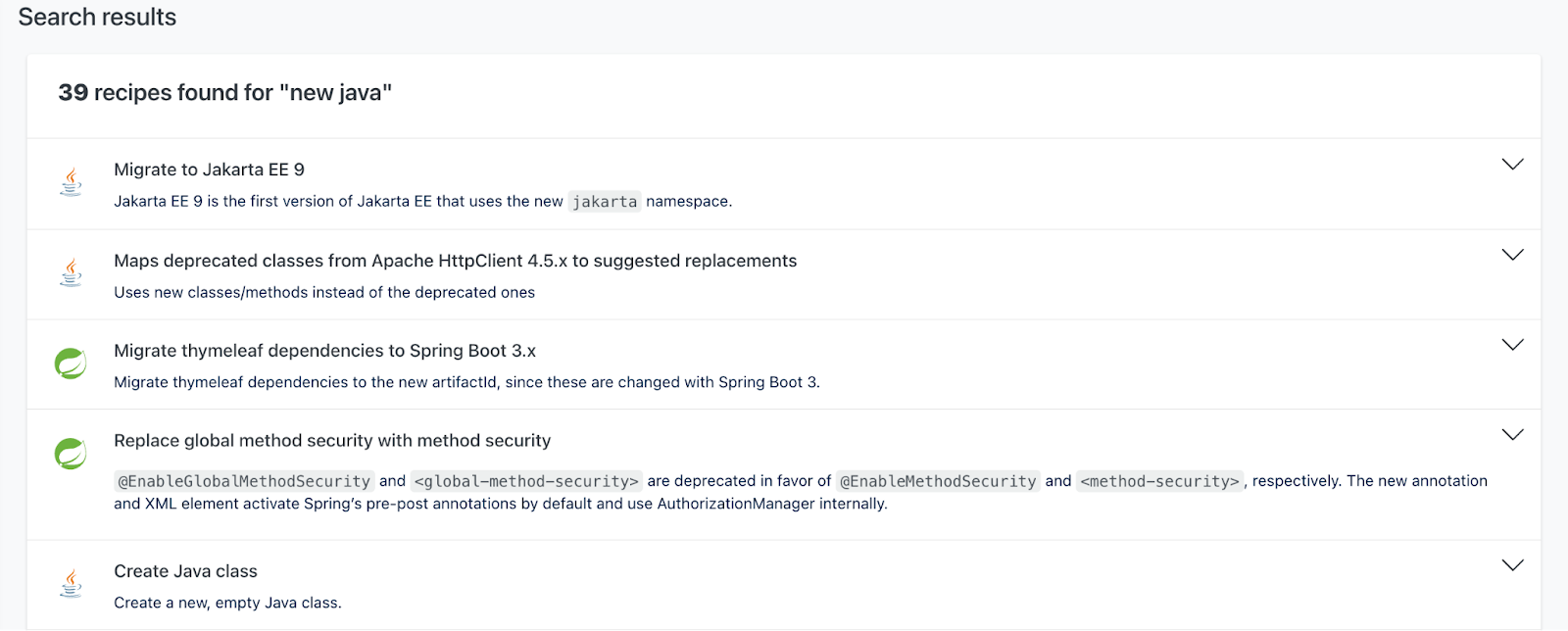
Synonymous phrases like “find method invocations” would not return the recipe “find method uses” (unless we laboriously added synonyms to the Lucene index). Typos like “upgade java” were a non-starter.
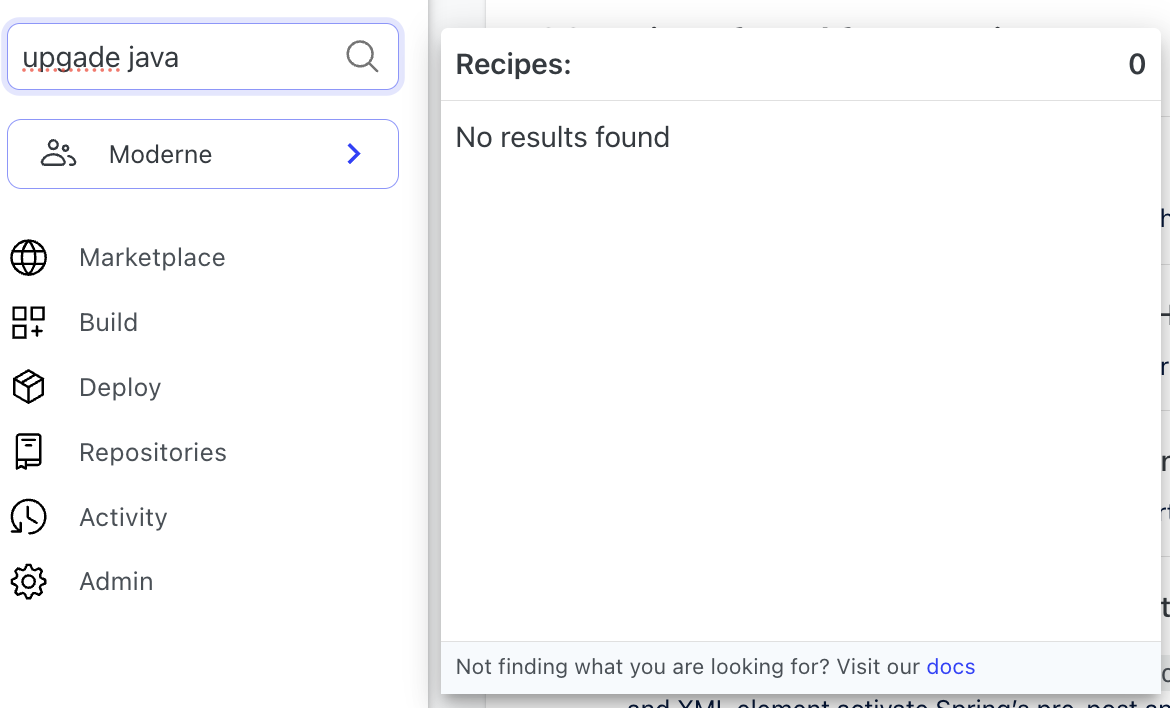
We knew that an AI-powered search solution could “think out of the box” and suggest many recipe options related to a user’s search. But we had to find the right combination of AI technologies and techniques that could narrow the search to highly applicable recipes.
Of course, we first wondered if a generative AI model would do the trick, but quickly learned it was not the right tool for the task. With more than 1400 recipes, the time to simply feed in the catalog as text to a generative model, was time- and cost-intensive. Even just feeding 400 recipes (~14,700 tokens) from the catalog for a search took 16 minutes on CPU using Code Llama 7b parameters. And because the longer the input text the slower the model, as we grow the recipe catalog, the search would become extremely slow. On top of that, the longer the context, the harder it is for a model to decipher noise from information (as described in this paper).
To deal with latency issues, we could have limited the text size, such as only feeding the recipe names instead of names and description, but decided that would leave out valuable information needed for search.
Alternatively, fine-tuning a model with specific data can ensure it is better adapted and efficient in the given context. However, the volume of data required for refining a generative model significantly exceeds our collection of recipes. Consider the example of the SQuAD 1.1 dataset, utilized for fine-tuning a model for question-answering, which contains over 100,000 questions along with their answers. To determine whether retrieval techniques or fine-tuning better suits your needs, it may be beneficial to consult this paper that contrasts the two.
That’s why we focused on using an AI embedding-based search that includes the embedding model, a vector database, and the retrieving technique. For our implementation, we were inspired by retrieval-augmented generation (RAG), but rather than a generation phase as the second step, we are doing a reranking step by using another model to rerank and filter the recipes to only include the highly applicable recipes. This approach made sense for our product because we wanted the search to expose the recommendations to the user in a clickable list that users could quickly select versus a chatbot.
Read on to learn all the details about our selection and testing of AI technologies and techniques for building our search function.
Building with AI embeddings: Fast and economical for search
The strength and flexibility of AI-based search come from embeddings. These embeddings are high-dimensional vectors that capture semantic relationships between phrases. This allows AI search engines to understand and retrieve information based on meaning rather than just keyword matching.
In addition to using the embedding model, you also must build a pipeline of tech, which includes a vector database, the input data to embed, and finally what retrieving technique to use to fetch the most likely elements based on a query.
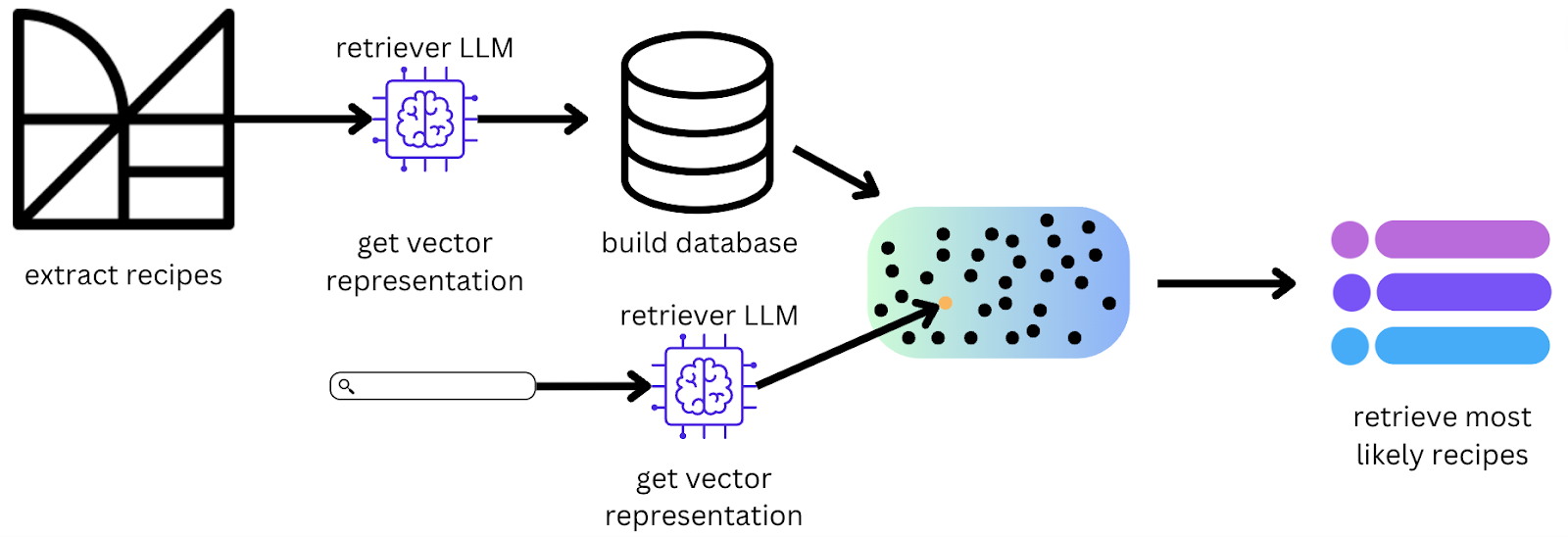
Selecting the right embedding model for the job
Embedding models are pre-trained large language models (LLMs) that use vast amounts of text data to learn complex patterns in language. LLMs can be used for a variety of tasks with natural language, such as generating text, translation, sentiment analysis, and information retrieval. There exist now multiple open-source LLMs that can be used as embedding models.
It’s important to experiment with various embedding models, including both general-purpose ones and those specifically fine-tuned for your particular domain, especially if you’re dealing with a highly specialized area. You can use the Massive Text Embedding Benchmark (MTEB) leaderboard to gather a list of candidate embedding models. Huggingface hosts open-source models and datasets, and maintains a multitude of machine-learning libraries notably used for generation, training, and evaluation.
When thinking of open-source software (OSS) LLMs that are specifically trained on code, Code Llama from Meta might be one of the first to come to mind. To create an embedding for a piece of text or code, you can combine the embeddings of each part of the text from Code Llama to form a single, summary-like embedding.
For our use case, we also evaluated BAAI’s bge-small-en-v1.5, a more generalist model which is trained for information retrieval. This is what we ended up using due to its better performance for our requirements compared to Code Llama (as you’ll see below).
Selecting the vector database for storing recipe embeddings
One of the key factors that could make or break our search pipeline was how we stored the embeddings. We needed a vector database for storing the embeddings for every recipe that could then be used to find which embedding was closer to a search query.
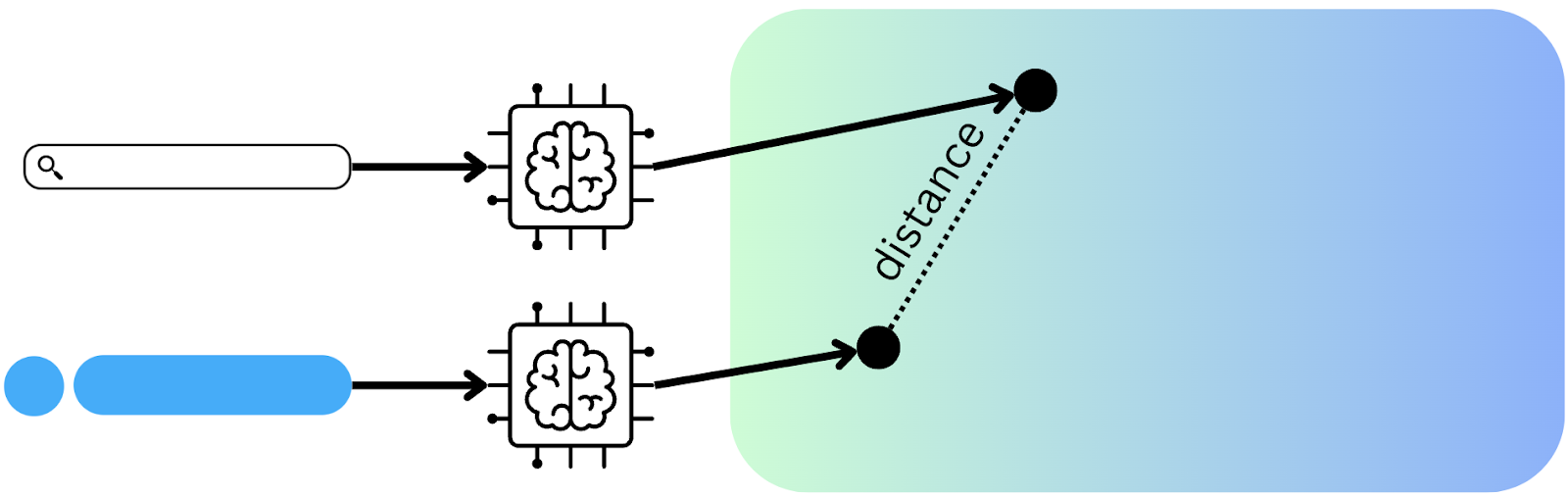
Figure 4 depicts a basic representation of a vector database. In it, each point symbolizes the embedding of a recipe, with the orange point representing the embedding of a search query. Although presented in a two-dimensional space, the underlying mathematical principles are consistent. The proximity of any two points indicates their relevance to each other. Thus, in a search operation, the goal is to retrieve the black dots that are nearest to the orange query dot, as they are most closely related to the search query.

We went with Meta’s OSS vector database called FAISS for its efficiency and easy implementation. FAISS operates by dividing the entire database into smaller subsets (see Figure 5), allowing it to concentrate its search efforts on specific segments rather than searching through the entire database at once.
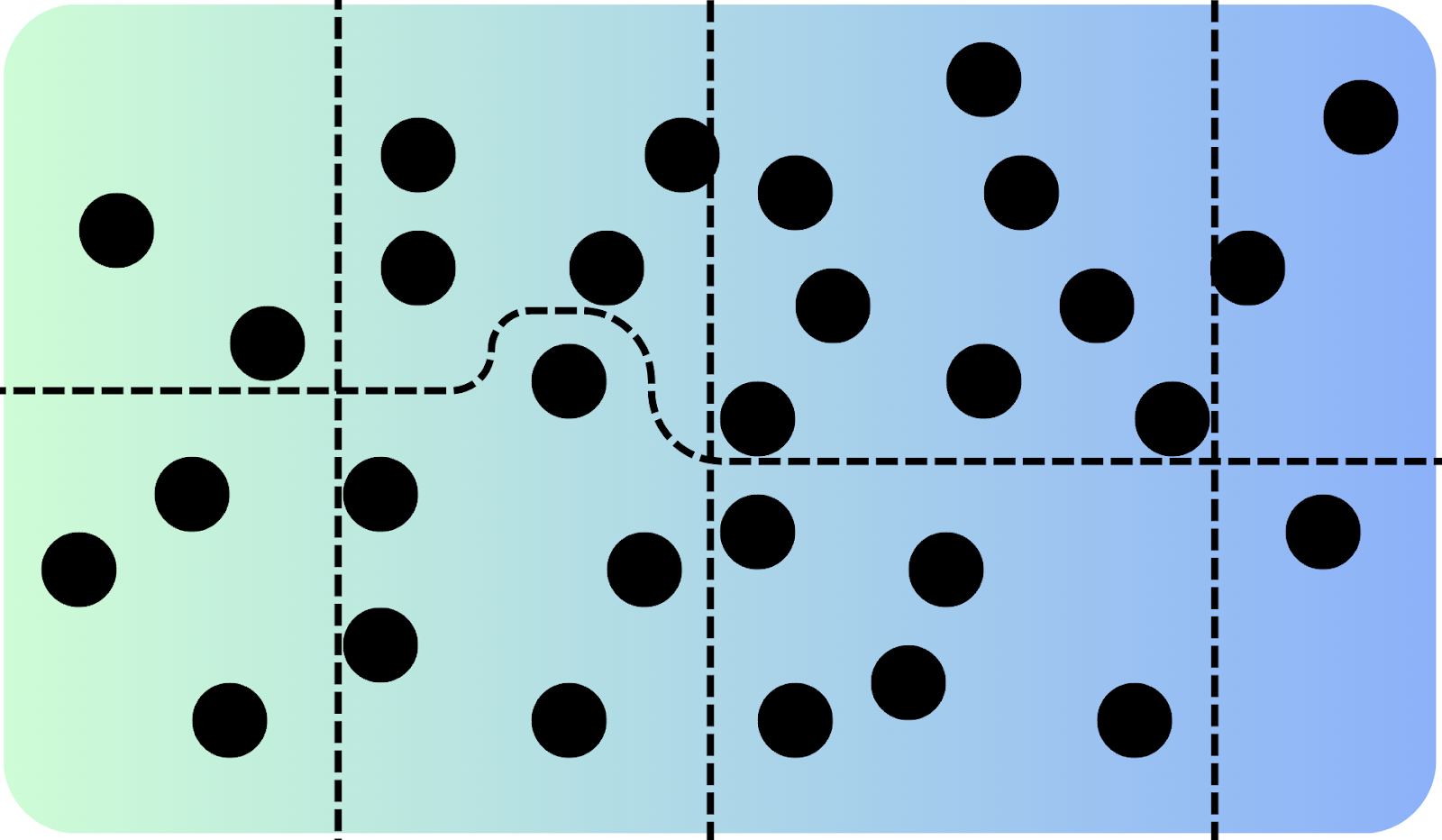
Focusing the input to the embedding model
Additionally, we had to find what text to pass to the embedding model. Too much information adds too much noise to the embedding, which confuses the model. However, not enough information could lead to the embedding not capturing the essence of the recipe and thus not being helpful.
We went with concatenating the name of the recipe with the description of the recipe since both contain useful information about the recipe. For instance, for the recipe “Find method usages” we could give the embedding model as input “Find method usages - Find method calls by pattern”.
The “just right” retrieving technique
There are many different options of retrievers you can use for returning a response from a query. We evaluated three different ones for our use case:
Regular retriever—Native to the vector database, this simple retriever is typically based on the distance between embeddings and the results are based on the closest elements to the query’s embedding.
Multi-query retriever—Uses a generation model (like OpenAI GPT or Code Llama) to produce a range of similar queries, rather than just one to produce a broader spectrum of queries, enhancing the diversity, and ensuring the retrieval of a comprehensive set of recipes.
Ensemble retriever—This technique fetches documents from multiple retrievers and then combines them.
We found that the Regular retriever worked fine for our use case, and did not add overhead that was unsupportable.
The Multi-Query retriever was not fit for many reasons. It comes with a significant computational cost, which in turn leads to higher latency. To get useful queries, you need an LLM that is good at generating, such as using an OpenAI model or an OSS model such as Mistral and Code Llama.
The Ensemble retriever is meant to bring the best of both worlds: embedding-based search and keyword matching. You can play with various ratios representing the respective weight assigned to the embedding-based search and the keyword-matching search. However, we did not see a significant performance difference for our use case beyond what we were getting with the Regular retriever.
Testing our AI-based search techniques
When designing some of the components of the search pipeline, we wanted to get a quick way to evaluate the setup. Of course, one could simply use the pipeline and search for a few recipes using queries, and manually verify if the results look accurate. This can be useful to see what kind of recipes are in the results to get a feeling on how the model is performing and what kind of queries work, but would also be time-consuming and not methodical.
Instead, we wanted a way to rapidly evaluate the techniques as we refined our implementation.
Establishing test search queries
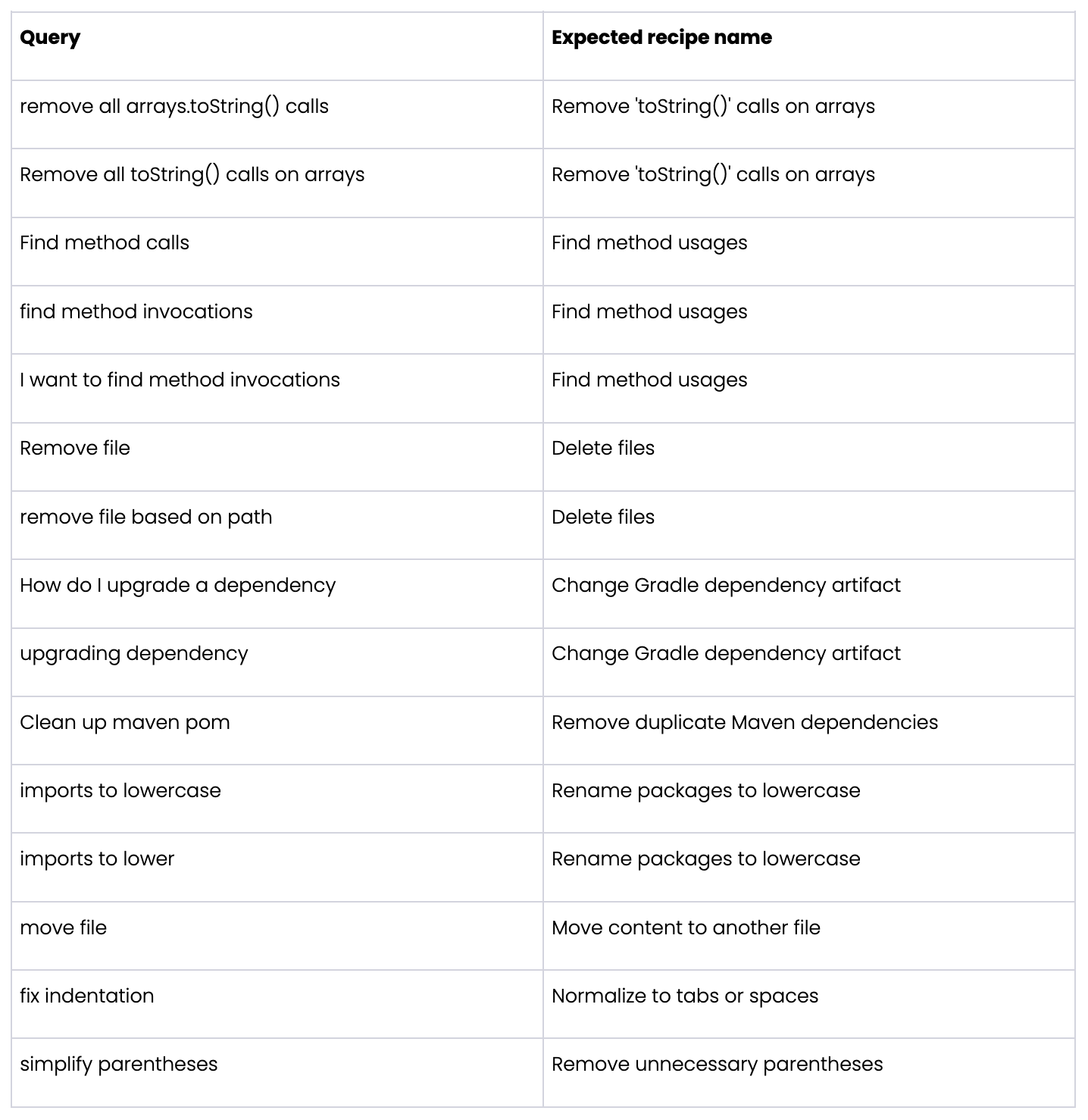
We came up with a very simple test set of common but difficult search queries we could expect to see on our platform:
AI-based search test results
At this point in our development, we had narrowed down our models to Code Llama embeddings and BAAI embeddings, and were ready to test them both using the same retrieval techniques.
We used the following setup for testing our techniques:
Loaded all the recipes in the vector database.
Used the test queries and checked if the expected recipe was featured in the results.
Retrieved the top five most likely recipes based on the test query.
Verified if the expected recipe was presented in the retrieved recipes.
We then calculated the model’s accuracy by dividing the number of times the expected recipe appeared by the total number of queries. Here are the results with different models and approaches:
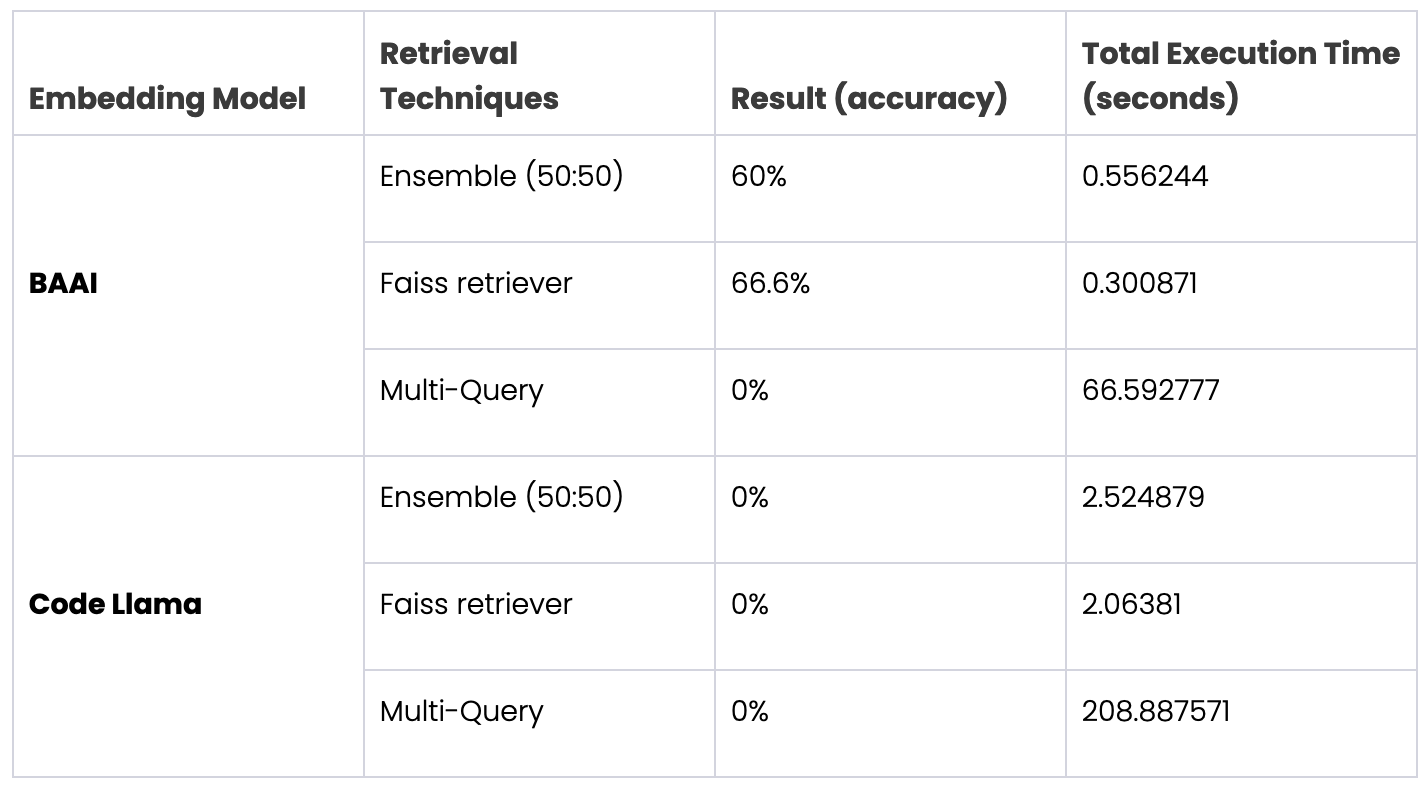
As you can see, using Code Llama as the embedding model was not successful. This is because Code Llama’s embeddings (or any other LLM for generation) are not trained for similarity search. To mitigate this, one could fine-tune an LLM (which would take time, lots of data, and lots of compute) or pivot to using a model such as BAAI, which is a general model that has been trained for similarity search. And that’s what we did.
Since we are in the domain of code, a model that is particularly fine-tuned for code would be useful here, but the lack of training for retrieval means it is better to go with a generalist model. If you were to build your search feature for a highly specific domain, we recommend you start by using a generalist model trained for retrieval first, and then resorting to fine-tuning only if needed.
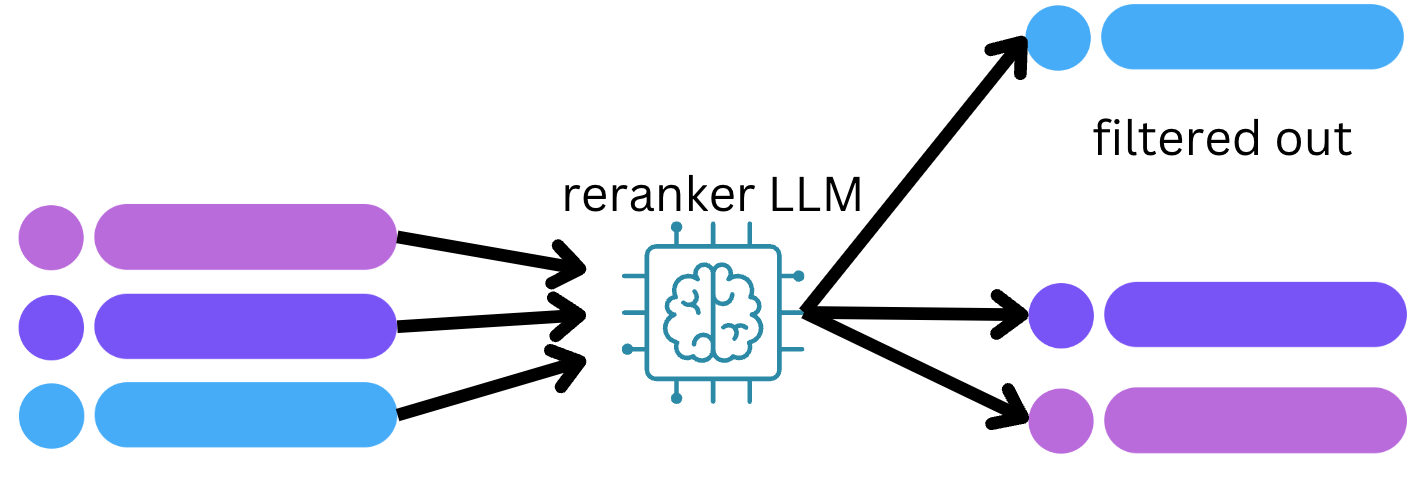
Adding reranking to finesse AI search results
Reranking is a technique to finesse your search results, up-leveling the more likely candidates. A reranking step allows us to sample a wide range of relevant recipes, without presenting all these choices as final results. Instead, you can filter and reorder them based on a scoring system. Essentially, this means you’re enabling a more advanced, albeit slower, model to search within a more focused subset of the available options.
One of the key things that make retrieval quick at search time, is that all the embeddings except for the query are already computed when loading the database. This means that all you have to do is compare the distance between the recipe’s embeddings and the query embedding, as shown in Figure 7, to calculate the relative rank.
For reranking, we used another model from BAAI called bge-reranker-large. It’s a larger model, which instead of sequentially taking the embeddings and looking at the distance to infer similarity, takes the concatenation of the query’s and recipe’s text, then calculates their embedding internally and outputs a similarity score. Having the model have access to the query’s and the recipe’s text together means it can better grasp the subtleties of the query and the recipe together.

So, why not just use that model alone? First of all, it’s a larger model (134MB versus 2.24GB), which means it takes significantly longer to get an embedding. Secondly, the embeddings for the recipes would have to be calculated on the fly as the search query comes in. That’s why we chose to use the larger model as a reranker, meaning that it takes the top-k recipes returned by the first smaller model and filters out the irrelevant ones. We can filter out the irrelevant ones by putting a threshold to what is considered a high-enough similarity score as returned by the reranker model.
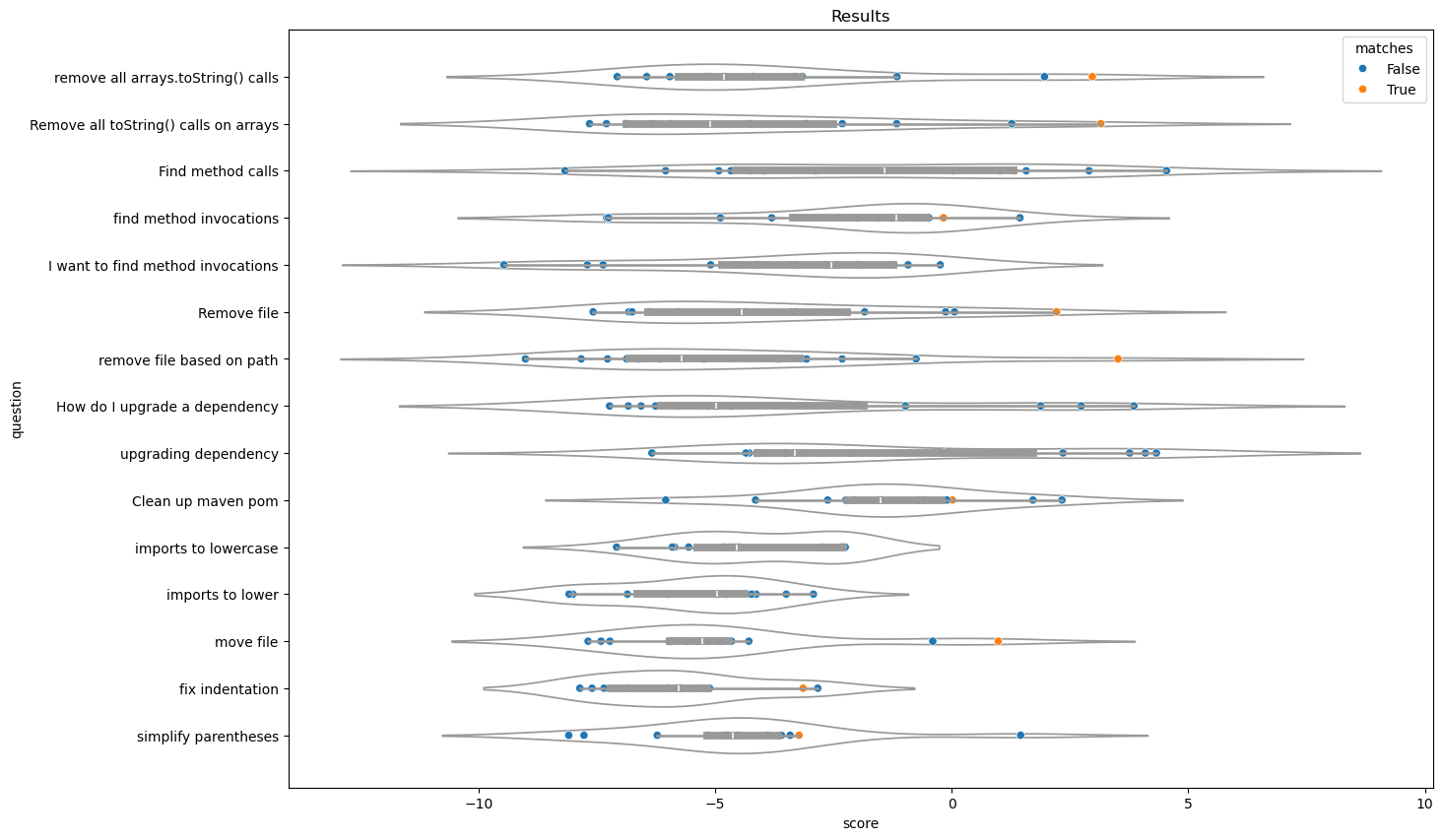
To decide which recipes to exclude, we needed to establish a threshold that differentiates between a high score for a relevant recipe and a low score for an irrelevant one. We charted a violin plot for each of our test queries to look at the distribution of their similarity score. On the plot, you can see the orange dots which represent the recipe we were looking for, and the blue dots representing other recipes. From there, we were able to set a threshold that was still generous but filtered out the completely irrelevant recipes. Setting the threshold should be based on the retrieval task of your own use case.
Deploying the AI-powered search on the Moderne Platform
Our final AI-based search pipeline is shown in Figure 11. It includes an embedding LLM, an in-memory vector database that retrieves similarities, and a slower reranking LLM to finesse the order of the results.
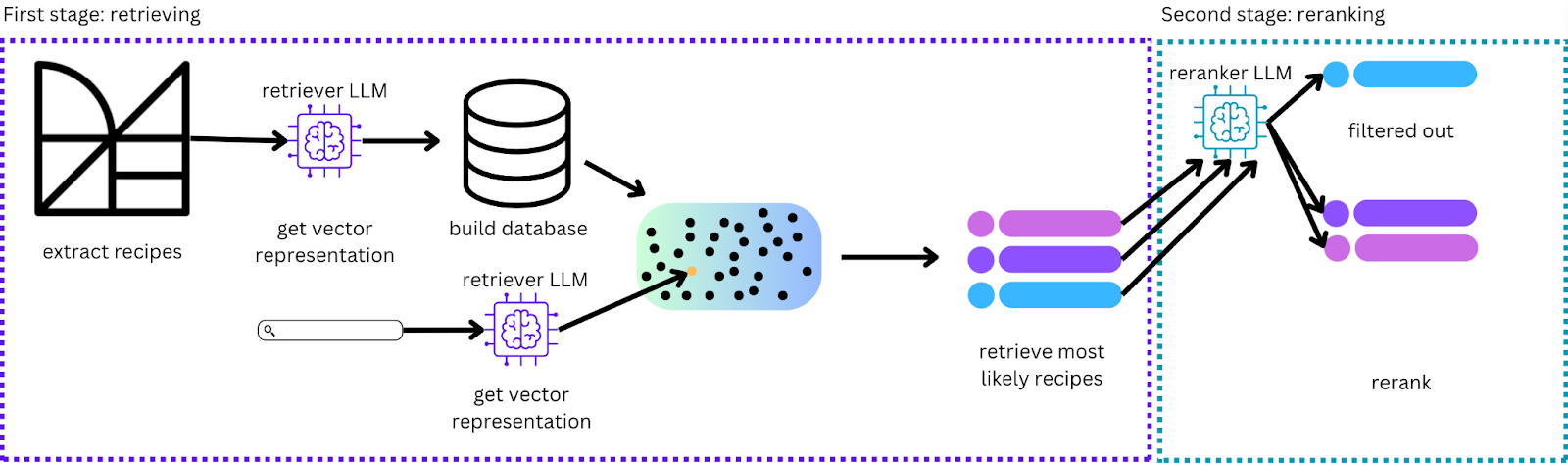
We used Langchain, an open-source Python library focused on deploying LLMs. All the features we were interested in trying were already accessible through their library. They also feature some great tutorials, which were very helpful when trying out the different setups which all come with their own set of subtle differences.
We deployed this search service as a side-car which ran the necessary Python code and models. This allowed the Moderne Platform to utilize this microservice for operations, enabling Java and Python microservices to be integrated and function in tandem.
At this stage, we also perform a secondary rerank to bump up recipes that cover more ground and have more capabilities. Composite recipes, which are composed of individual recipes such as migration of libraries, can be more desirable therefore we want to bump them up. You basically can incorporate any additional reranking you want to do based on your goal.
We recognize the value of keyword-based matching, particularly for experts familiar with the precise name of the recipe they seek. For such cases, our platform offers the option to revert to keyword matching by enclosing the query in quotation marks whilst keeping AI assisted search enabled. Additional tips and tricks can be found in our documentation.
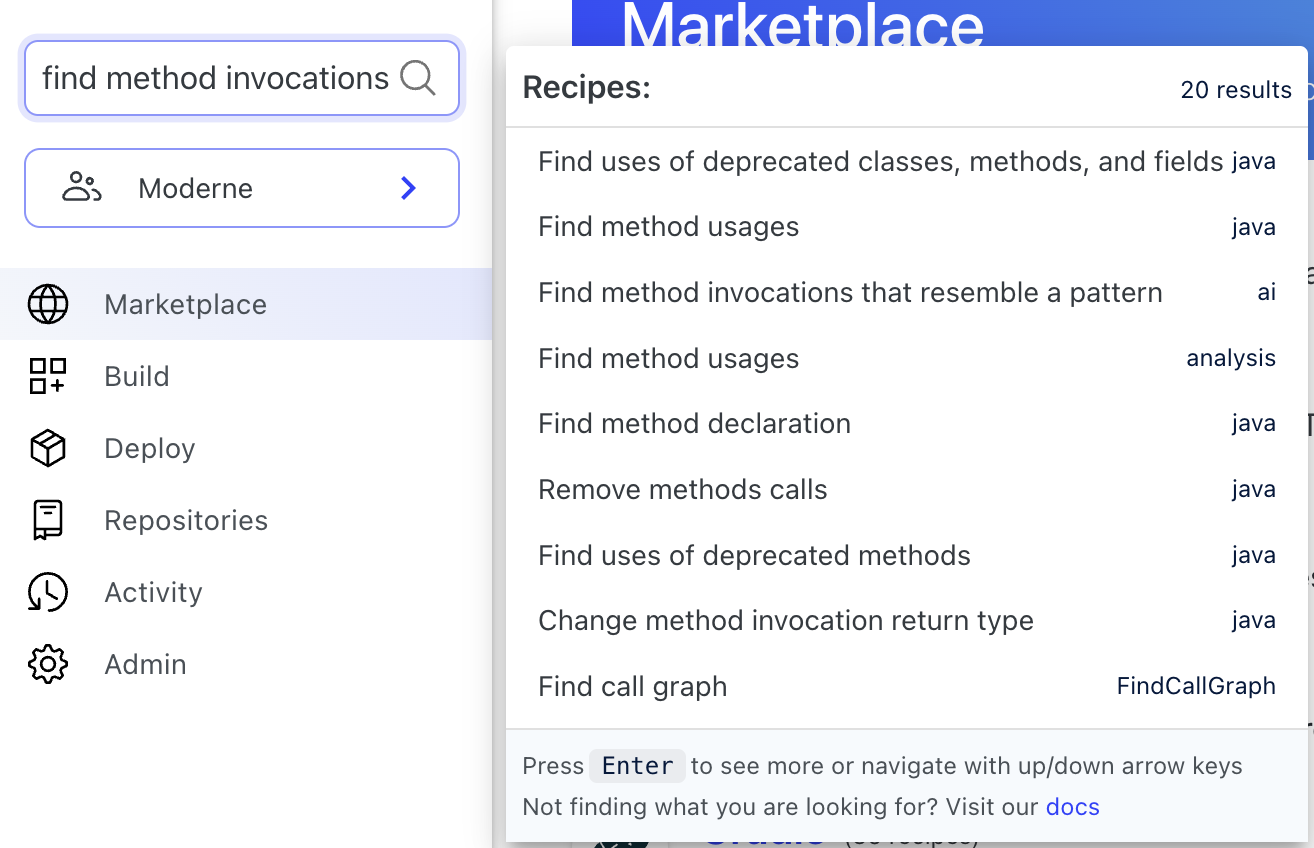
The final AI-based search in action is shown in Figure 12, identifying responses if searching for “find method invocations.” Interestingly, the search not only retrieves the exact recipe we sought under “Find method usages” despite our use of “invocation” instead of “usage,” but it also allows the user to uncover additional related recipes that may pertain to their query. Also, because of the choices we made during development, we’re pleased to offer an AI-based search that is just as quick as the Lucene-based search from the user perspective.
Try out the AI-based search for yourself in the free trial of the Moderne Platform.
On to our next AI developments
We were able to devise a very efficient search using AI embeddings, and hope that this blog post can help others too.
Our next step in incorporating AI into the Moderne Platform is to recommend recipes for a codebase. We utilize a model that examines a codebase and smartly samples code snippets to inform its suggestions for enhancements or modernizations. We then post-validate these AI-generated recommendations by using the AI search explained in this blog to see if any recipes are applicable to each recommendation. This essentially extends our AI search, which not only helps users find recipes but can also be used as part of a recommendation pipeline that samples your code. Keep an eye out for the Moderne dashboard, which will feature a list of recommended recipes tailored to your code.
Related posts


